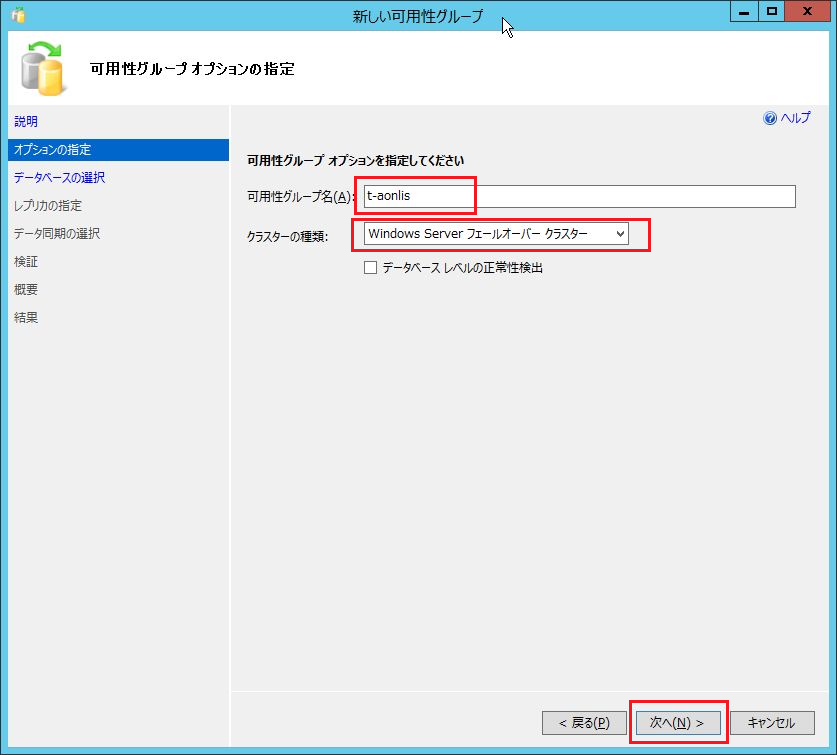
こんにちは、技術4課の多田です。
昨年、「AWS Cloud Development Kit」(以下、AWS CDK) が開発者プレビューですが、発表されました。
AWS CDK 開発者プレビュー
GitHub – awslabs/awscdk
「AWS CDK」の特徴は、プラグラマブルに CloudFormation のプロビジョングができるので、アプリケーションの開発からインフラまで一貫した開発を行えるのがメリットになります。
今回は CDK Workshop を使って、「AWS CDK」を使ってみます。
普段は CloudFormaiton を使ってプロビジョニングを行なっているので、 CloudFormation との使いっぷりを気にしつつ触っていきます。
TL;DR
- CDK のワークショップを使って、 CDK を実践した
- CDK を使ってみて CloudFormation との比較をした
AWS CDK の概要
「AWS CDK」 はコードでクラウドインフラストラクチャを定義し、CloudFormation でプロビジョニングするためのオープンソースのソフトウェア開発フレームワークです。
サポートされている言語は以下の通りです。今後は Python もサポート予定とのことです。
- TypeScript
- JavaScript
- Java
- .Net
AWS CDK の実践
準備作業
環境は、AWS Cloud(以下、Cloud9) を使います。「AWS CDK」には以下の要件が必要です。
- AWS CLI
- Node.js (バージョンが8.11以上)
Cloud9 には AWS CLI がインストールされているのでインストール不要です。
また、Cloud9 のデフォルトの Node.js ではバージョンが満たしてないため、バージョンをあげます。
ワークショップでは、バージョンを「v8.12.0」にする必要があるため左記バージョンまでアップデートします。
$ node -v
v6.16.0
$ nvm install v8.12.0
Downloading https://nodejs.org/dist/v8.12.0/node-v8.12.0-linux-x64.tar.xz...
####################################################################################################################################################################### 100.0%
Now using node v8.12.0 (npm v6.4.1)
$ node -v
v8.12.0
次に、「AWS CDK」も導入します。ワークショップでは、バージョンを意図的に「0.22」を指定しています。
$ npm install -g aws-cdk@0.22.0
/home/ec2-user/.nvm/versions/node/v8.12.0/bin/cdk -> /home/ec2-user/.nvm/versions/node/v8.12.0/lib/node_modules/aws-cdk/bin/cdk
+ aws-cdk@0.22.0
added 276 packages from 255 contributors in 18.188s
$ cdk --version
0.22.0 (build 644ebf5)
東京リージョンにリソースを作りたいので、「AWS_DEFAULT_REGION」の変数をセットします。
「AWS CDK」のコマンドで cdk doctor コマンドを打つと現状の設定を確認できて便利なので、上記の変数をセットした後確認します。
$ export AWS_DEFAULT_REGION=ap-northeast-1
$ cdk doctor
ℹ️ CDK Version: 0.22.0 (build 644ebf5)
ℹ️ AWS environment variables:
- AWS_DEFAULT_REGION = ap-northeast-1
- AWS_CLOUDWATCH_HOME = /opt/aws/apitools/mon
- AWS_PATH = /opt/aws
- AWS_AUTO_SCALING_HOME = /opt/aws/apitools/as
- AWS_ELB_HOME = /opt/aws/apitools/elb
ℹ️ No CDK environment variables
AWS CDK プロジェクトの作成
次に TypeScript のサンプルプロジェクトを作成していきます。
$ mkdir cdk-workshop && cd cdk-workshop
$ cdk init sample-app --language typescript
Applying project template sample-app for typescript
Initializing a new git repository...
Executing npm install...
npm notice created a lockfile as package-lock.json. You should commit this file.
npm WARN cdk-workshop@0.1.0 No repository field.
npm WARN cdk-workshop@0.1.0 No license field.
# Useful commands
* `npm run build` compile typescript to js
* `npm run watch` watch for changes and compile
* `cdk deploy` deploy this stack to your default AWS account/region
* `cdk diff` compare deployed stack with current state
* `cdk synth` emits the synthesized CloudFormation template
プロジェクト関連ファイルについて解説があったためまとめます。
lib/cdk-workshop-stackts.ts はCDKアプリケーションのメインスタックが定義されるbin/cdk-workshop.ts はCDKアプリケーションのエントリポイントになるlib/cdk-workshop-stack.ts で定義されているスタックをロードされるpackage.json はnpmモジュールのマニフェストファイルであるcdk.json はツールキットにアプリの実行方法を指示する
- 今回は
node bin/cdk-workshop.js になる
tsconfig.json はTypeScriptの設定が定義されるnode_modules ディレクトリにはnpmによって管理され、プロジェクトのすべての依存関係を含まれる
![]()
サンプルプロジェクトでは、以下のリソースを作ります。
- SQS キュー
- SNS トピック
- SQS キューを SNS トピックでサブスクライブ
import sns = require('@aws-cdk/aws-sns');
import sqs = require('@aws-cdk/aws-sqs');
import cdk = require('@aws-cdk/cdk');
export class CdkWorkshopStack extends cdk.Stack {
constructor(scope: cdk.App, id: string, props?: cdk.StackProps) {
super(scope, id, props);
const queue = new sqs.Queue(this, 'CdkWorkshopQueue', {
visibilityTimeoutSec: 300
});
const topic = new sns.Topic(this, 'CdkWorkshopTopic');
topic.subscribeQueue(queue);
}
}
アプリケーションコードから CloudFormation テンプレートの確認とデプロイ
cdk synth を実行すると CDK で作る、 CloudFormation のテンプレートを確認できます。
$ cdk synth
Resources:
CdkWorkshopQueue50D9D426:
Type: AWS::SQS::Queue
Properties:
VisibilityTimeout: 300
Metadata:
aws:cdk:path: CdkWorkshopStack/CdkWorkshopQueue/Resource
CdkWorkshopQueuePolicyAF2494A5:
Type: AWS::SQS::QueuePolicy
Properties:
PolicyDocument:
Statement:
- Action: sqs:SendMessage
Condition:
ArnEquals:
aws:SourceArn:
Ref: CdkWorkshopTopicD368A42F
Effect: Allow
Principal:
Service: sns.amazonaws.com
Resource:
Fn::GetAtt:
- CdkWorkshopQueue50D9D426
- Arn
Version: "2012-10-17"
Queues:
- Ref: CdkWorkshopQueue50D9D426
Metadata:
aws:cdk:path: CdkWorkshopStack/CdkWorkshopQueue/Policy/Resource
CdkWorkshopTopicD368A42F:
Type: AWS::SNS::Topic
Metadata:
aws:cdk:path: CdkWorkshopStack/CdkWorkshopTopic/Resource
CdkWorkshopTopicCdkWorkshopQueueSubscription88D211C7:
Type: AWS::SNS::Subscription
Properties:
Endpoint:
Fn::GetAtt:
- CdkWorkshopQueue50D9D426
- Arn
Protocol: sqs
TopicArn:
Ref: CdkWorkshopTopicD368A42F
Metadata:
aws:cdk:path: CdkWorkshopStack/CdkWorkshopTopic/CdkWorkshopQueueSubscription/Resource
CDKMetadata:
Type: AWS::CDK::Metadata
Properties:
Modules: aws-cdk=0.22.0,@aws-cdk/aws-cloudwatch=0.22.0,@aws-cdk/aws-iam=0.22.0,@aws-cdk/aws-kms=0.22.0,@aws-cdk/aws-s3-notifications=0.22.0,@aws-cdk/aws-sns=0.22.0,@aws-cdk/aws-sqs=0.22.0,@aws-cdk/cdk=0.22.0,@aws-cdk/cx-api=0.22.0,jsii-runtime=node.js/v8.12.0
続いて、CloudFormation のデプロイを行なっていきます。
「AWS CDK」アプリを初めてデプロイするときに「bootstrap stack」をインストールする必要があります。
「bootstrap stack」では、CloudFormation テンプレートを格納する S3 が用意されます。
$ cdk bootstrap
Bootstrapping environment xxxxxxxxxxx/ap-northeast-1...
CDKToolkit: creating CloudFormation changeset...
0/2 | 04:30:07 | CREATE_IN_PROGRESS | AWS::S3::Bucket | StagingBucket
0/2 | 04:30:09 | CREATE_IN_PROGRESS | AWS::S3::Bucket | StagingBucket Resource creation Initiated
1/2 | 04:30:30 | CREATE_COMPLETE | AWS::S3::Bucket | StagingBucket
2/2 | 04:30:32 | CREATE_COMPLETE | AWS::CloudFormation::Stack | CDKToolkit
Environment xxxxxxxxxxx/ap-northeast-1 bootstrapped.
コマンドが成功すると、 CloudFormation スタックが作成されS3バケットが作成されます。
![]()
$ cdk deploy
This deployment will make potentially sensitive changes according to your current security approval level (--require-approval broadening).
Please confirm you intend to make the following modifications:
~中略~~
CdkWorkshopStack
Stack ARN:
arn:aws:cloudformation:ap-northeast-1:xxxxxxxxxxx:stack/CdkWorkshopStack/a5bd1260-31a4-11e9-87b8-0ec110ab8a1e
CloudFormation のコンソールを確認するとスタックが出来上がっているのを確認できました。
![]()
次の作業のためにサンプルで作成したリソースを削除します。
lib/cdk-workshop-stack.tsを以下のように編集します。
import cdk = require('@aws-cdk/cdk');
export class CdkWorkshopStack extends cdk.Stack {
constructor(scope: cdk.App, id: string, props?: cdk.StackProps) {
super(scope, id, props);
}
}
変更後のリソースの変化の確認の仕方は、cdk diff で確認可能です。
$ cdk diff
IAM Statement Changes
~中略~
Resources
[-] AWS::SQS::Queue CdkWorkshopQueue50D9D426 destroy
[-] AWS::SQS::QueuePolicy CdkWorkshopQueuePolicyAF2494A5 destroy
[-] AWS::SNS::Topic CdkWorkshopTopicD368A42F destroy
[-] AWS::SNS::Subscription CdkWorkshopTopicCdkWorkshopQueueSubscription88D211C7 destroy
変更内容が問題なければ、再度 cdk deploy を実行します。
$ cdk deploy
CdkWorkshopStack: deploying...
CdkWorkshopStack: creating CloudFormation changeset...
~中略~
CdkWorkshopStack
Stack ARN:
arn:aws:cloudformation:ap-northeast-1:xxxxxxxxxxx:stack/CdkWorkshopStack/a5bd1260-31a4-11e9-87b8-0ec110ab8a1e
Lambda と API Gateway の構成方法
次に、AWS Lambda(以下、Lambda)、Amazon API Gateway(以下、APIGW)のサーバーレス構成を CDK で行います。
まず最初に、Lambda のコードを作成します。
binやlibと同じ階層に lambda/hello.js を作成し、以下のコードを記載します。
APIGW の URI にアクセスすると、「Hello, CDK! You’ve hit /(アクセスしたパス)」と返すコードになります。
exports.handler = async function(event) {
console.log('request:', JSON.stringify(event, undefined, 2));
return {
statusCode: 200,
headers: { 'Content-Type': 'text/plain' },
body: `Hello, CDK! You've hit ${event.path}\n`
};
};
加えて、 Constructs ライブラリを追加します。このライブラリは AWS サービスごとにあり、AWSのベストプラクティスに従った設定を内包しています。
今回でいうと、 Lambda を定義したり、 APIGW を定義するには上記のライブラリをインストールする必要があります。
$ npm install @aws-cdk/aws-lambda@0.22.0
npm WARN cdk-workshop@0.1.0 No repository field.
npm WARN cdk-workshop@0.1.0 No license field.
+ @aws-cdk/aws-lambda@0.22.0
updated 1 package and audited 1901 packages in 3.194s
found 0 vulnerabilities
$ npm install @aws-cdk/aws-apigateway@0.22.0
npm WARN cdk-workshop@0.1.0 No repository field.
npm WARN cdk-workshop@0.1.0 No license field.
+ @aws-cdk/aws-apigateway@0.22.0
added 1 package from 1 contributor and audited 2476 packages in 6.122s
found 0 vulnerabilities
APIGW と Lambda を統合するコードを lib/cdk-workshop-stack.tsに追記します。
cdk diff で変更箇所の確認してみます。
$ cdk diff
The CdkWorkshopStack stack uses assets, which are currently not accounted for in the diff output! See https://github.com/awslabs/aws-cdk/issues/395
IAM Statement Changes
~中略~
Outputs
[+] Output Endpoint/Endpoint Endpoint8024A810: {"Value":{"Fn::Join":["",["https://",{"Ref":"EndpointEEF1FD8F"},".execute-api.",{"Ref":"AWS::Region"},".",{"Ref":"AWS::URLSuffix"},"/",{"Ref":"EndpointDeploymentStageprodB78BEEA0"},"/"]]},"Export":{"Name":"CdkWorkshopStack:Endpoint8024A810"}}
それでは、デプロイしてみます。
$ cdk deploy
Do you wish to deploy these changes (y/n)? y
CdkWorkshopStack: deploying...
Updated: lambda (zip)
CdkWorkshopStack: creating CloudFormation changeset...
~中略~
CdkWorkshopStack
Outputs:
CdkWorkshopStack.Endpoint8024A810 = https://vam8k4pk2e.execute-api.ap-northeast-1.amazonaws.com/prod/
Stack ARN:
arn:aws:cloudformation:ap-northeast-1:xxxxxxxxxxxx:stack/CdkWorkshopStack/a5bd1260-31a4-11e9-87b8-0ec110ab8a1e
デプロイされたエンドポイントに対して、アクセスしてみたら想定通りの結果が帰ってきました。
$ curl https://vam8k4pk2e.execute-api.ap-northeast-1.amazonaws.com/prod/
Hello, CDK! You've hit /
DynamoDB リソースの追加
次に、Amazon DynamoDB(以下、DynamoDB)のリソースを追加します。
アクセスした URI のパスを DynamoDB のテーブルに記録する処理を定義するものを定義します。
まずは、DynamoDB の Constructs ライブラリをインストールします。
$ npm install @aws-cdk/aws-dynamodb@0.22.0
npm WARN cdk-workshop@0.1.0 No repository field.
npm WARN cdk-workshop@0.1.0 No license field.
+ @aws-cdk/aws-dynamodb@0.22.0
added 3 packages from 1 contributor and audited 2564 packages in 10.132s
found 0 vulnerabilities
lambda/hitcounter.js に以下のコードを追加します。
const { DynamoDB, Lambda } = require('aws-sdk');
exports.handler = async function(event) {
console.log("request:", JSON.stringify(event, undefined, 2));
// create AWS SDK clients
const dynamo = new DynamoDB();
const lambda = new Lambda();
// update dynamo entry for "path" with hits++
await dynamo.updateItem({
TableName: process.env.HITS_TABLE_NAME, # DynamoDBテーブルの名前
Key: { path: { S: event.path } },
UpdateExpression: 'ADD hits :incr',
ExpressionAttributeValues: { ':incr': { N: '1' } }
}).promise();
// call downstream function and capture response
const resp = await lambda.invoke({
FunctionName: process.env.DOWNSTREAM_FUNCTION_NAME, #Lambda関数名
Payload: JSON.stringify(event)
}).promise();
console.log('downstream response:', JSON.stringify(resp, undefined, 2));
// return response back to upstream caller
return JSON.parse(resp.Payload);
};
lib/hitcounter.ts は次のように編集します。
import cdk = require('@aws-cdk/cdk');
import lambda = require('@aws-cdk/aws-lambda');
import dynamodb = require('@aws-cdk/aws-dynamodb');
export interface HitCounterProps {
/** the function for which we want to count url hits **/
downstream: lambda.Function;
}
export class HitCounter extends cdk.Construct {
/** allows accessing the counter function */
public readonly handler: lambda.Function;
constructor(scope: cdk.Construct, id: string, props: HitCounterProps) {
super(scope, id);
const table = new dynamodb.Table(this, 'Hits');
table.addPartitionKey({ name: 'path', type: dynamodb.AttributeType.String });
this.handler = new lambda.Function(this, 'HitCounterHandler', {
runtime: lambda.Runtime.NodeJS810,
handler: 'hitcounter.handler',
code: lambda.Code.asset('lambda'),
environment: {
DOWNSTREAM_FUNCTION_NAME: props.downstream.functionName,
HITS_TABLE_NAME: table.tableName
}
});
// grant the lambda role read/write permissions to our table
table.grantReadWriteData(this.handler.role);
// grant the lambda role invoke permissions to the downstream function
props.downstream.grantInvoke(this.handler.role);
}
}
lib/cdk-workshop-stack.ts は次のように編集します。
import cdk = require('@aws-cdk/cdk');
import lambda = require('@aws-cdk/aws-lambda');
import apigw = require('@aws-cdk/aws-apigateway');
import { HitCounter } from './hitcounter';
export class CdkWorkshopStack extends cdk.Stack {
constructor(scope: cdk.App, id: string, props?: cdk.StackProps) {
super(scope, id, props);
const hello = new lambda.Function(this, 'HelloHandler', {
runtime: lambda.Runtime.NodeJS810,
code: lambda.Code.asset('lambda'),
handler: 'hello.handler'
});
const helloWithCounter = new HitCounter(this, 'HelloHitCounter', {
downstream: hello
});
// defines an API Gateway REST API resource backed by our "hello" function.
new apigw.LambdaRestApi(this, 'Endpoint', {
handler: helloWithCounter.handler
});
}
}
それではデプロイします。
$ cdk deploy
~中略~
CdkWorkshopStack
Outputs:
CdkWorkshopStack.Endpoint8024A810 = https://vam8k4pk2e.execute-api.ap-northeast-1.amazonaws.com/prod/
Stack ARN:
arn:aws:cloudformation:ap-northeast-1:xxxxxxxxxxxx:stack/CdkWorkshopStack/a5bd1260-31a4-11e9-87b8-0ec110ab8a1e
URI にアクセスしてみます。
$ curl -i https://vam8k4pk2e.execute-api.ap-northeast-1.amazonaws.com/prod/
Hello, CDK! You've hit /
$ curl -i https://vam8k4pk2e.execute-api.ap-northeast-1.amazonaws.com/prod/hello
Hello, CDK! You've hit /hello
$ curl -i https://vam8k4pk2e.execute-api.ap-northeast-1.amazonaws.com/prod/test
Hello, CDK! You've hit /test
3回アクセスしたので、 DynamoDB のテーブルに3つレコードが登録されていることを確認できました。![]() 最後は、作ったリソースを削除しますが、
最後は、作ったリソースを削除しますが、cdk destroy を実行します。
$ cdk destroy
Are you sure you want to delete: CdkWorkshopStack (y/n)? y
CdkWorkshopStack: destroying...
~中略~
CdkWorkshopStack: destroyed
AWS CDK と CloudFormation の比較考察
「AWS CDK」を使ってみてのメリット/デメリットを CloudFormation を使う場合と比較してみます。
AWS CDK と CloudFormation を比較してみて感じたメリット
- 普段書き慣れている言語であれば、YAML や JSON の CloudFormation よりは書きやすい
- 感覚的にリソースのデプロイが CloudFormation よりは簡易
- !Ref のような関数を使わなくても関連リソースの定義ができるのはよかった
- 例えば、Lambda の IAM ロール設定が
table.grantReadWriteData(this.handler.role); だけなので、CloudFormation のように ARN を指定しなくていいのでシンプルだと感じた
- IDEで書いているため、コードの中でのライブラリ定義の参照元などをすぐに調べやすい
AWS CDK と CloudFormation を比較してみて感じたデメリット
- サポートされてる言語の習得が必須であること
- 自由度が高く CloudFormation テンプレートを書けるのでプロジェクト内での運用ルールを考える必要はありそう
- CloudFormation のサポートしている JSON や YAMLの方が開発者が馴染むのなら CloudFormation の方が良い
まとめ
「AWS CDK」を使った AWS リソース構成の実践と、 CloudFormation との使い分けを自分なりに考察してみました。
現状サポートされている言語が少ないものの、個人的には今後の Python サポートが楽しみです。
プログマブルに条件分岐や繰り返しの処理などを組み合わせて、 CloudFormation だけではできなかった運用ができそうです。
なお、 Constructs ライブラリのレファレンスはこちらです。
本リリースまでに CloudFormation で作ったソースを置き換えたりしてみて更に使い込んでみたいです。