AWSの様々なサービスでは、ログをS3バケットに保管できる仕様になっています。
しかし、残念なことにAmazon InspectorにはS3バケットへの出力機能がありません。
今回は、マルチアカウント・マルチリージョン環境でのInspectorの検知結果を、どのように1つのS3バケットに集約するかについて考えていきます。
1.Amazon Inspectorの評価結果の出力機能について
Amazon Inspectorの脆弱性の評価結果を、S3に出力することはできません。
評価結果には以下のいずれかでアクセスします。
- マネージメントコンソールからPDFまたはHTMLで評価レポートをダウンロード
- マネージメントコンソールから検知結果を確認、CSVでダウンロード
- SNS、イベントで通知される評価結果を指すURLからAPIで取得
3について説明を加えておきます。
Inspectorでは評価をする度に、arn:aws:inspector:ap-northeast-1:xxxxxxxxxxxx:target/xxxx/template/yyyyy/run/zzzzのようなARNが発行され、Amazon EventBridgeでイベント検知できます。
また、Inspectorの設定項目にオプションとしてSNS Topicが設定でき、こちらでも同様のARNを通知できます。
そのARNに対し、list-findingsをすれば、個々の検知結果のARNを取得できます。
~$ aws inspector list-findings --assessment-run-arns arn:aws:inspector:ap-northeast-1:xxxxxxxxxxxx:target/0-g3O5KfZD/template/0-fRLbBTop/run/0-BV8rzFjN
{
"findingArns": [
"arn:aws:inspector:ap-northeast-1:xxxxxxxxxxxx:target/0-g3O5KfZD/template/0-fRLbBTop/run/0-BV8rzFjN/finding/0-O0Zfj3eA",
"arn:aws:inspector:ap-northeast-1:xxxxxxxxxxxx:target/0-g3O5KfZD/template/0-fRLbBTop/run/0-BV8rzFjN/finding/0-NwJjopiW",
"arn:aws:inspector:ap-northeast-1:xxxxxxxxxxxx:target/0-g3O5KfZD/template/0-fRLbBTop/run/0-BV8rzFjN/finding/0-z991gY9x",
"arn:aws:inspector:ap-northeast-1:xxxxxxxxxxxx:target/0-g3O5KfZD/template/0-fRLbBTop/run/0-BV8rzFjN/finding/0-MMoPGegp",
"arn:aws:inspector:ap-northeast-1:xxxxxxxxxxxx:target/0-g3O5KfZD/template/0-fRLbBTop/run/0-BV8rzFjN/finding/0-yRKz72Kl",
"arn:aws:inspector:ap-northeast-1:xxxxxxxxxxxx:target/0-g3O5KfZD/template/0-fRLbBTop/run/0-BV8rzFjN/finding/0-7S2CNIcg"
]
}
上記で得た個々のARNに対し、describe-findingsをすれば、検知結果の詳細を取得できます。
~$ aws inspector describe-findings --finding-arns arn:aws:inspector:ap-northeast-1:xxxxxxxxxxxx:target/0-g3O5KfZD/template/0-fRLbBTop/run/0-BV8rzFjN/finding/0-O0Zfj3eA
{
"findings": [
{
"arn": "arn:aws:inspector:ap-northeast-1:xxxxxxxxxxxx:target/0-g3O5KfZD/template/0-fRLbBTop/run/0-BV8rzFjN/finding/0-O0Zfj3eA",
"schemaVersion": 1,
"service": "Inspector",
"serviceAttributes": {
"schemaVersion": 1,
"assessmentRunArn": "arn:aws:inspector:ap-northeast-1:xxxxxxxxxxxx:target/0-g3O5KfZD/template/0-fRLbBTop/run/0-BV8rzFjN",
"rulesPackageArn": "arn:aws:inspector:ap-northeast-1:406045910587:rulespackage/0-bBUQnxMq"
},
<省略>
"id": "Disable root login over SSH",
"title": "Instance i-09095f80a71c9d8f6 is configured to allow users to log in with root credentials over SSH, without having to use a command authenticated by a public key. This increases the likelihood of a successful brute-force attack.",
"description": "This rule helps determine whether the SSH daemon is configured to permit logging in to your EC2 instance as root.",
"recommendation": "To reduce the likelihood of a successful brute-force attack, we recommend that you configure your EC2 instance to prevent root account logins over SSH. To disable SSH root account logins, set PermitRootLogin to 'no' in /etc/ssh/sshd_config and restart sshd. When logged in as a non-root user, you can use sudo to escalate privileges when necessary. If you want to allow public key authentication with a command associated with the key, you can set **PermitRootLogin** to 'forced-commands-only'.",
"severity": "Medium",
"numericSeverity": 6.0,
"confidence": 10,
"indicatorOfCompromise": false,
"attributes": [
{
"key": "INSTANCE_ID",
"value": "i-09095f80a71c9d8f6"
}
],
"userAttributes": [],
"createdAt": 1583825759.119,
"updatedAt": 1583825759.119
}
],
"failedItems": {}
}
ここまで見ると、AWSに詳しい方なら、SNS、EventBridge、Lambda等の組み合わせ等で、S3への出力を自動化することも可能と推測すると思います。
しかし、もう少し他の方法も探ってみます。
2.Security Hubのイベント通知について
Security Hubには、GuardDutyやInspectorなどの検知結果を受け取れる機能があります。
Security HubにS3への出力機能があれば、Security Hub経由でInspectorの結果をS3に集約できると思ったのですが、残念ながらありませんでした。
ただし、Security Hubをソースとしたイベントは、Inspectorをソースとしたイベントと通知される内容が異なります。
| イベントのソース |
イベント通知の中身 |
| Inspector |
脆弱性をたくさん検知しても、ARNが1つだけ通知される。
それに対して、list-findings、describe-findingsをする必要がある。 |
| SecurityHub |
脆弱性をたくさん検知したら、個別にdescribe-findingsの内容が通知される。 |
Security Hubのイベント通知内容なら、以下のフローでS3バケットに集約できそうです。
Lambda関数で頑張る必要がありません。
- Inspectorで評価した内容をSecurityHubに統合
- SecurityHubのイベントをEventBridgeでトリガーにする
- EventBridgeからKinesis Data Firehoseに送る
- Kinesis Data FirehoseからS3に送る
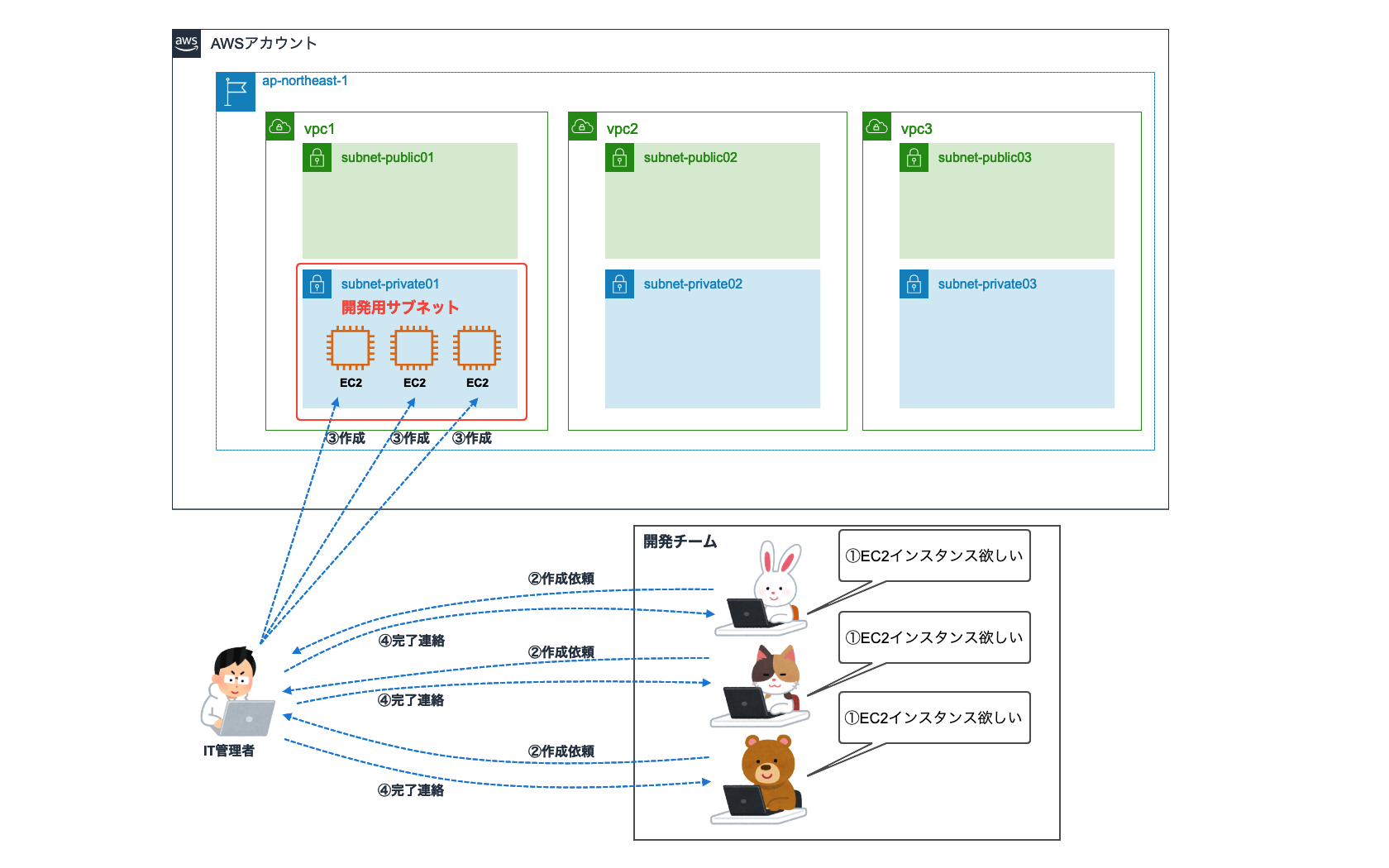
3.構成図
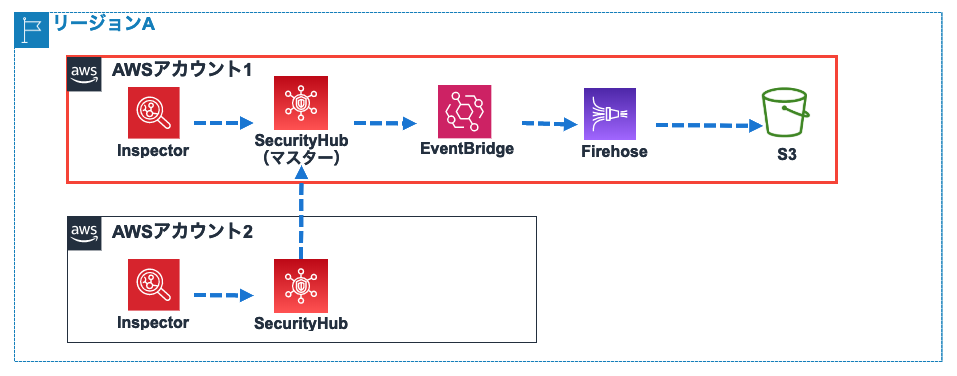
3-1.シングルリージョンの場合
Security Hubには他アカウントの同一リージョンの検知結果を取り込める機能があります。
したがって、単一リージョンのみ利用の場合は、1つのマスターアカウントに集約できます。
![]()
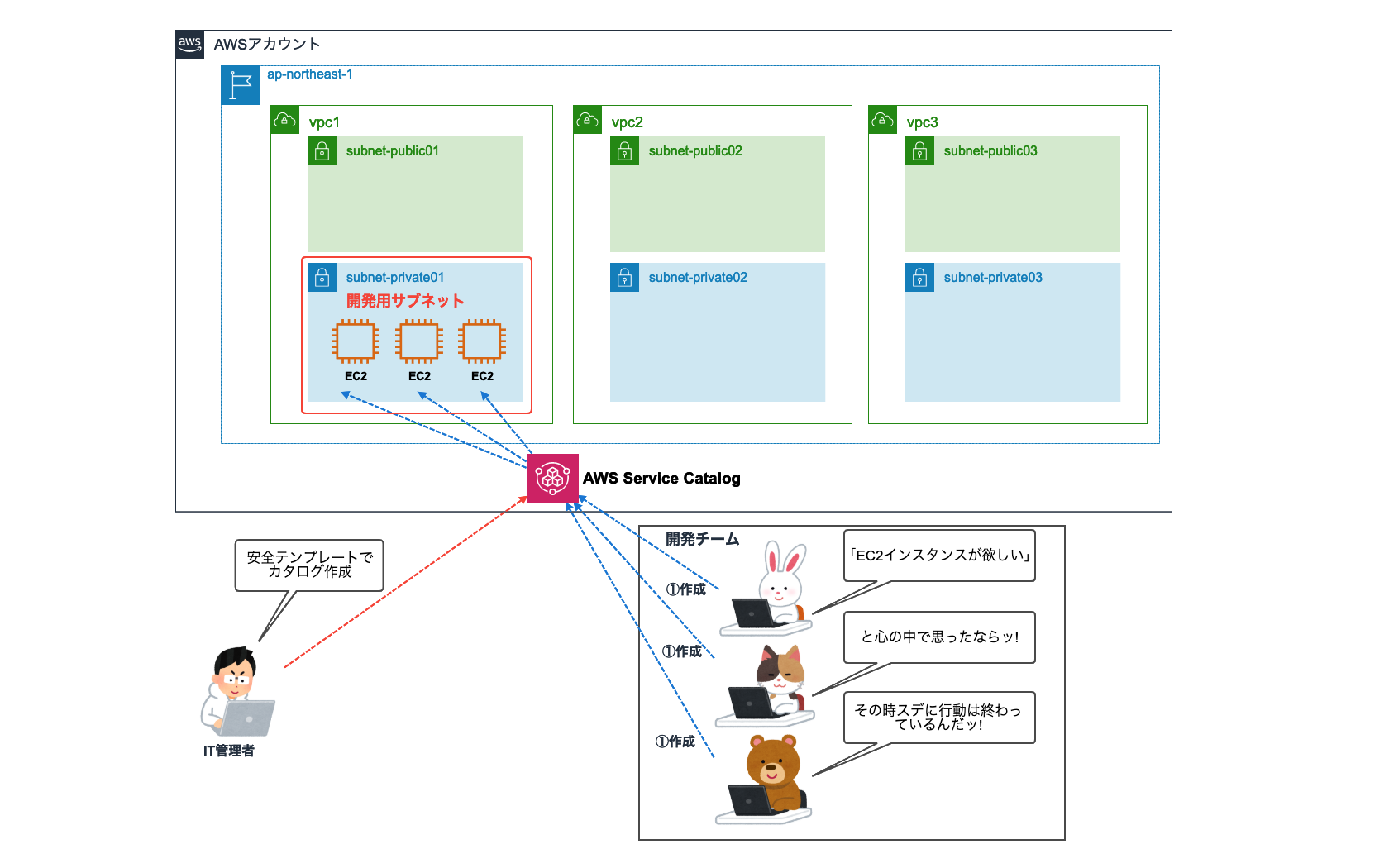
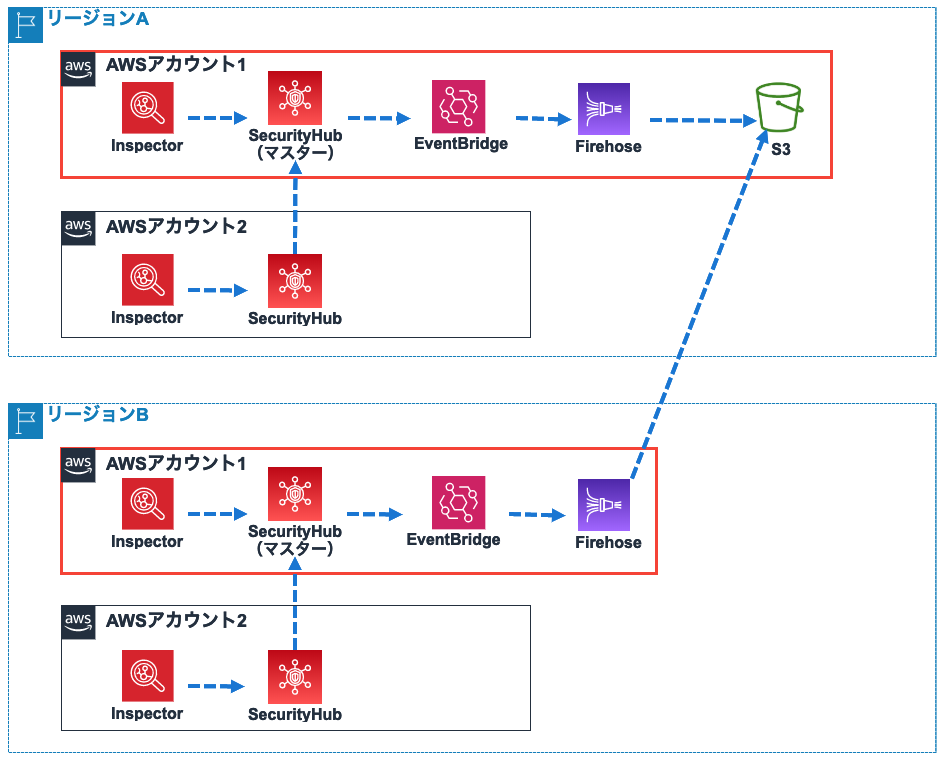
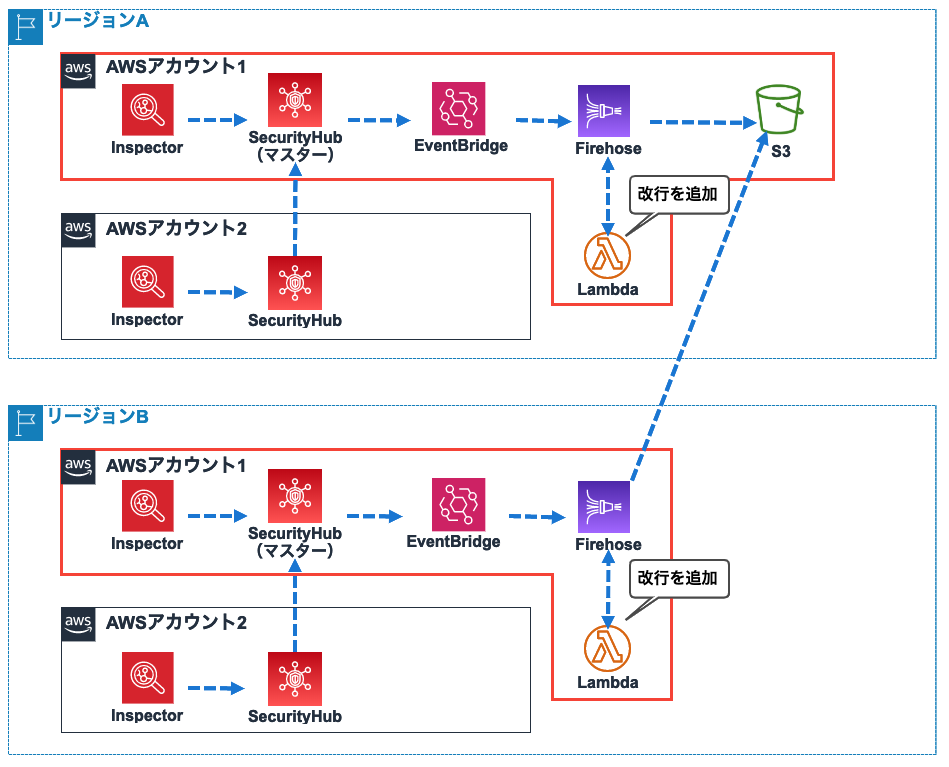
3-2.マルチリージョンの場合
複数リージョンを使用している場合は、リージョンごとにSecurity Hubのマスターアカウントを作る必要があります。
![]()
4.設定
具体的な設定をみていきます。
4-1.S3バケット作成
バケット名は何でもいいのですが、今回はaws-logs-inspector-xxxxxxxxxxxx としておきます。
(xxxxxxxxxxxxはAWSアカウントID)
4-2.Security Hub設定
Security HubにInspectorを統合
各アカウントの各リージョンでSecurity HubにInspectorが統合されていることを確認します。
![]()
Security Hubのマスターアカウントにメンバーアカウントを追加
SecurityHubマスターアカウントでメンバーとなるアカウントを追加します。
その後、メンバー側で承認をすれば、ステータスが有効となります。
![]()
4-3.Firehose設定
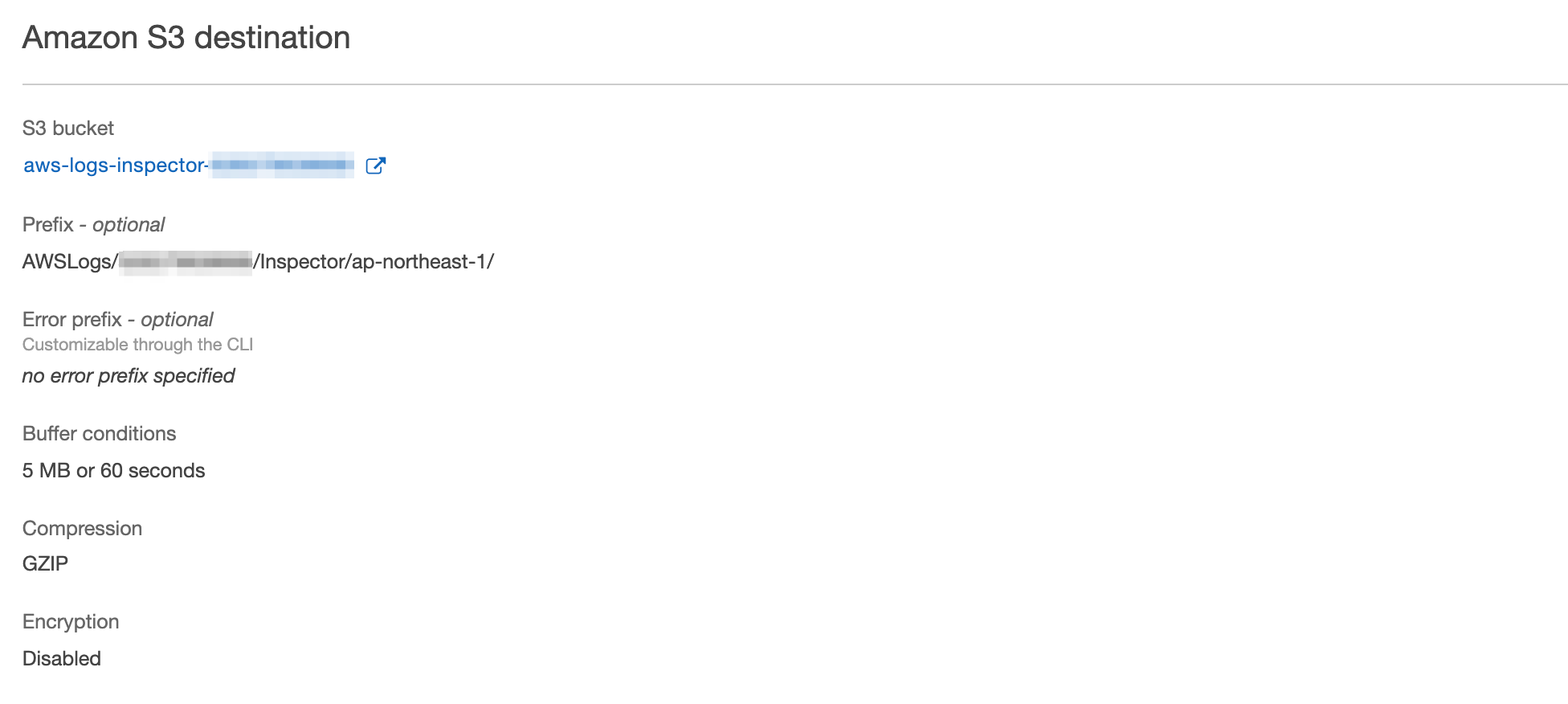
Kinesis Data Firehoseを作成します。
Destinationとして、先ほど作成したS3バケットを指定します。
また、複数アカウント、複数リージョンから受け取るので、Prefixを下記のように指定します。
このPrefixには少し問題があるのですが、後で述べます。
| パラメータ |
設定値 |
| Prefix |
AWSLogs/<マスターアカウントのAWSアカウントID>/Inspector/<リージョン>/ |
![]()
4-4.EventBridge設定
Security HubのマスターアカウントでEventBridgeルールの設定をします。
![]()
イベントパターンは下記のようにします。
sourceがaws.securityhubだけだと、GuardDutyなど他サービスからの通知も含んでしまいそうなので、ProductNameでInspectorにフィルタしています。
{
"source": [
"aws.securityhub"
],
"detail-type": [
"Security Hub Findings - Imported"
],
"detail": {
"findings": {
"ProductFields": {
"aws/securityhub/ProductName": [
"Inspector"
]
}
}
}
}
ターゲットには先ほど作成したFirehoseを指定します。
5.動作確認
Inspectorを動作させ、S3バケットに保存されていれば成功です。
S3バケット内は、Firehoseの標準機能により、自動的に年・月・日などの階層構造となります。
![]()
6.残された問題と解決方法
一通りの仕組みが出来上がりましたが、ここで2つの問題に気づいてしまいました。
問題1. 異なるアカウントのログも同じフォルダに入ってしまう
4-3.Firehose設定 で「このPrefixには少し問題がある」と述べました。
アカウントIDでフォルダの分類ができていません。
Prefixは、AWSLogs/<マスターアカウントのAWSアカウントID>/Inspector/<リージョン>/としました。
しかし、AWSアカウントが複数(例えばxxxxxxxxxxxx、yyyyyyyyyyyy)あった場合は、以下のように分類したいかもしれません。
- AWSLogs/xxxxxxxxxxxx/Inspector/<リージョン>/
- AWSLogs/yyyyyyyyyyyy/Inspector/<リージョン>/
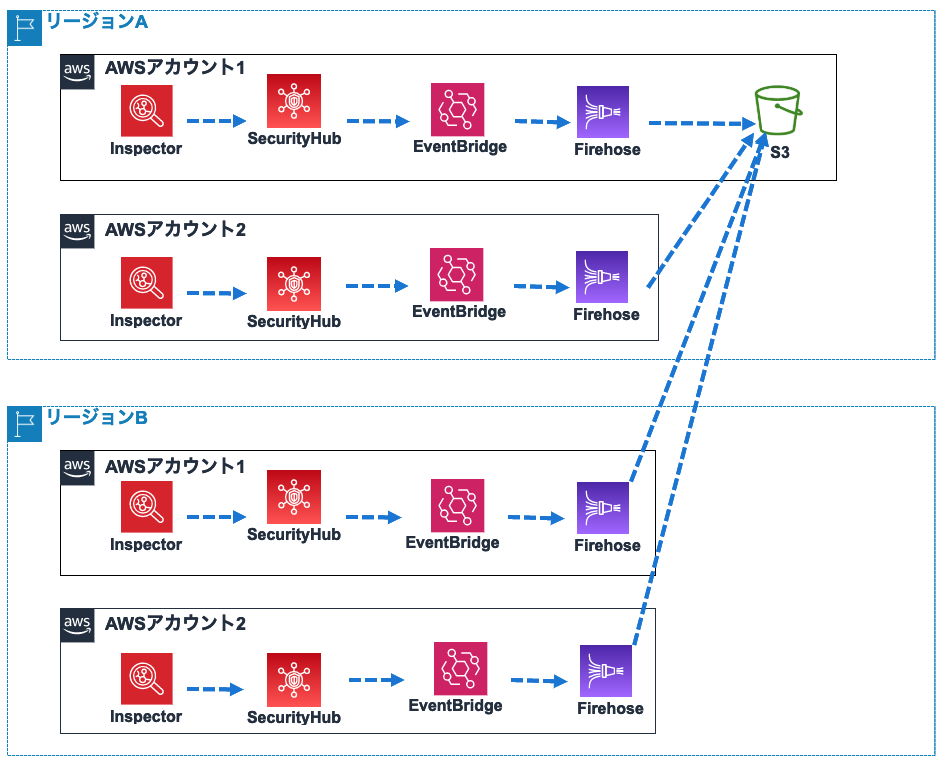
解決方法としては、アカウントごとにFirehoseを分け、それぞれのPrefixを設定することが思いつきます。
![]()
この構成の問題は、管理するリソースが増えることです。
ただし、CloudFormationなどを使えば、リソースが増えることによる設定の手間はあまり考えないでいいかもしれません。
問題2.JSONが改行されないで1行で保存される
S3に保存されたファイルの中身をみてみると、JSON形式のメッセージが改行されずに1行に連結されてました。
例えば、Inspectorが1回の評価で5つの脆弱性を検知した場合、下記のように5つの検知結果が1行になって保存されます。
{ 検知結果1 }{ 検知結果2 }{ 検知結果3 }{ 検知結果4 }{ 検知結果5 }
しかし、下記のように改行されて保存して欲しい場合もあるのではないでしょうか。
{ 検知結果1 }
{ 検知結果2 }
{ 検知結果3 }
{ 検知結果4 }
{ 検知結果5 }
解決方法としては、FirehoseからLambdaを連携させて、改行文字を追加する方法があります。
![]()
具体的には、まずLambda関数を作成します。
base64でエンコードされているdataが渡されるので、それをデコードし、更にString型に変換して末尾に改行文字を追加しています。
import base64
def lambda_handler(event, context):
output = []
for record in event['records']:
payload = base64.b64decode(record['data']).decode('utf-8')
payload = str(payload) + '\n'
payload = payload.encode("UTF-8")
# Do custom processing on the payload here
output_record = {
'recordId': record['recordId'],
'result': 'Ok',
'data': base64.b64encode(payload)
}
output.append(output_record)
print('Successfully processed {} records.'.format(len(event['records'])))
return {'records': output}
次にFirehoseの「Transform source records with AWS Lambda」 で、その関数を指定します。
![]()
まとめ
- InspectorのログはSecurity Hubのイベントから取得可能。
- Firehoseを使うとS3への保存は便利。改行されない場合は、Lambdaで処理可能。






























 成功のメッセージが出力されたら[閉じる]をクリックします。
成功のメッセージが出力されたら[閉じる]をクリックします。



































































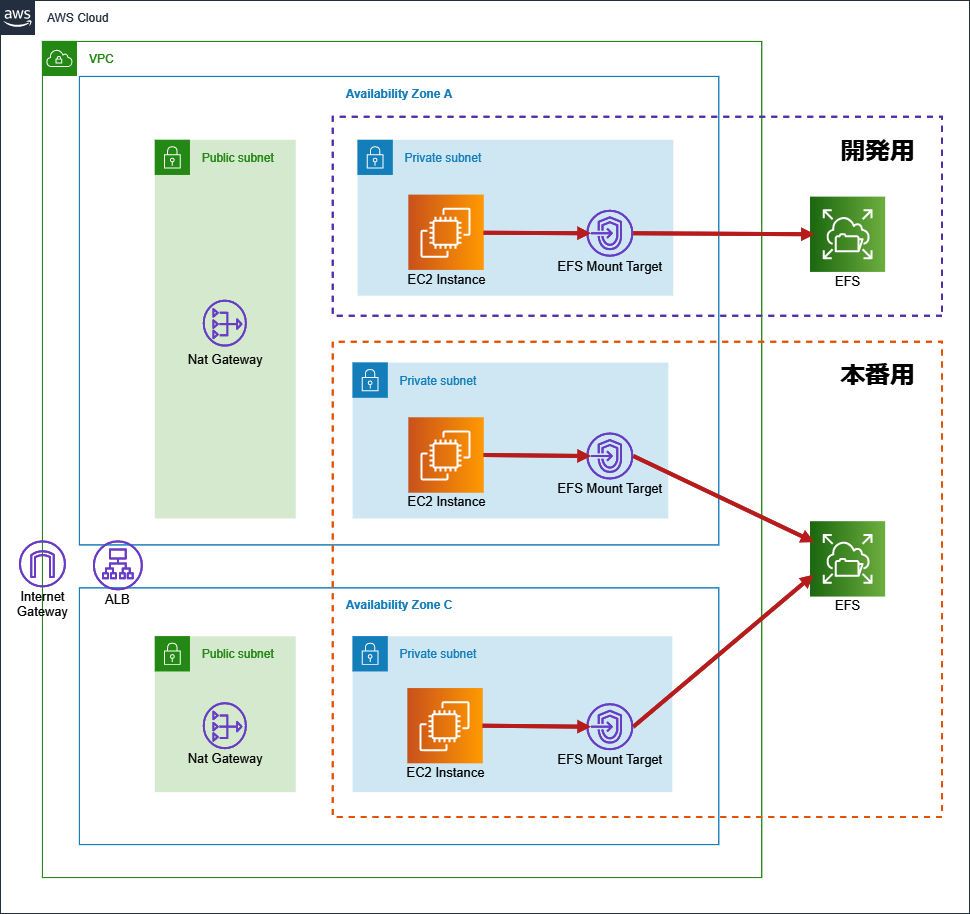
 ここでのポイントとしては、マウントターゲットをAZ-aの「開発用EC2が設置されたサブネット」にしていることです。
ここでのポイントとしては、マウントターゲットをAZ-aの「開発用EC2が設置されたサブネット」にしていることです。

 マウントツールのインストール方法の解説が記されていますね。親切ですね~
マウントツールのインストール方法の解説が記されていますね。親切ですね~ ふむふむ、おや?
ふむふむ、おや? 「DNSホスト名」が無効になっていますね。
「DNSホスト名」が無効になっていますね。 No.3のマウント用コマンドが表示されるようになりましたね。
No.3のマウント用コマンドが表示されるようになりましたね。




































