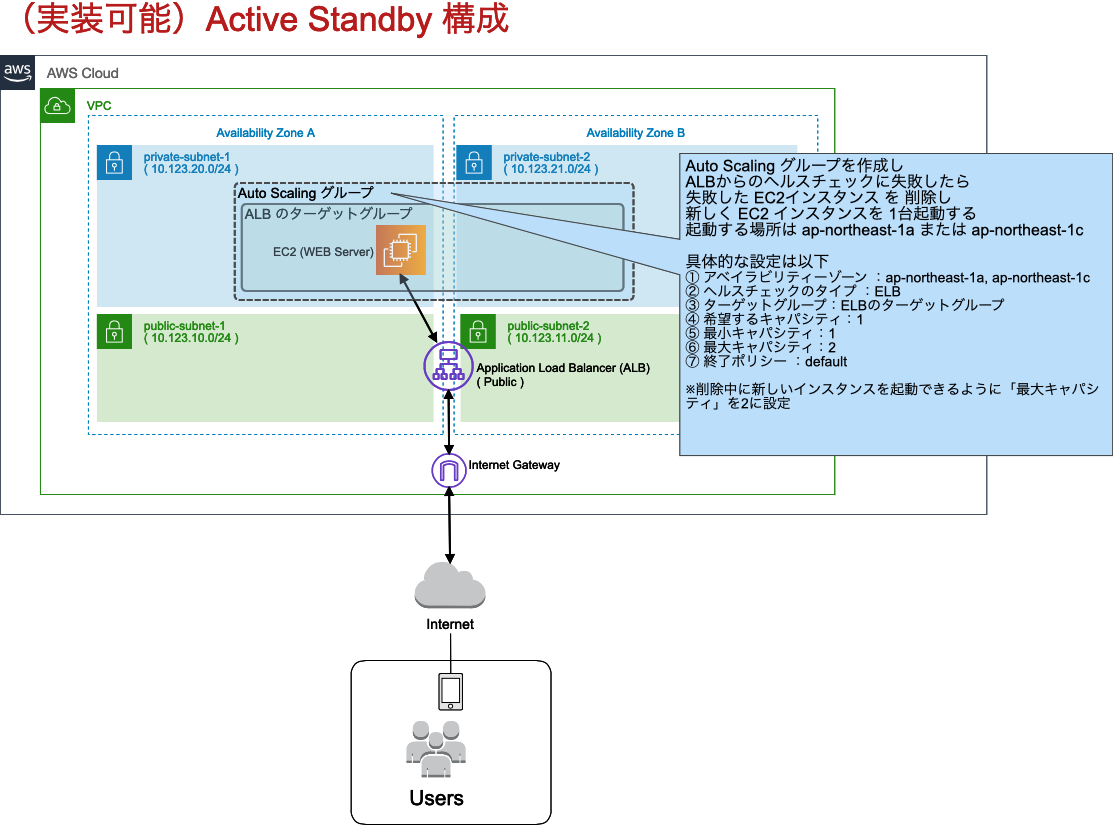
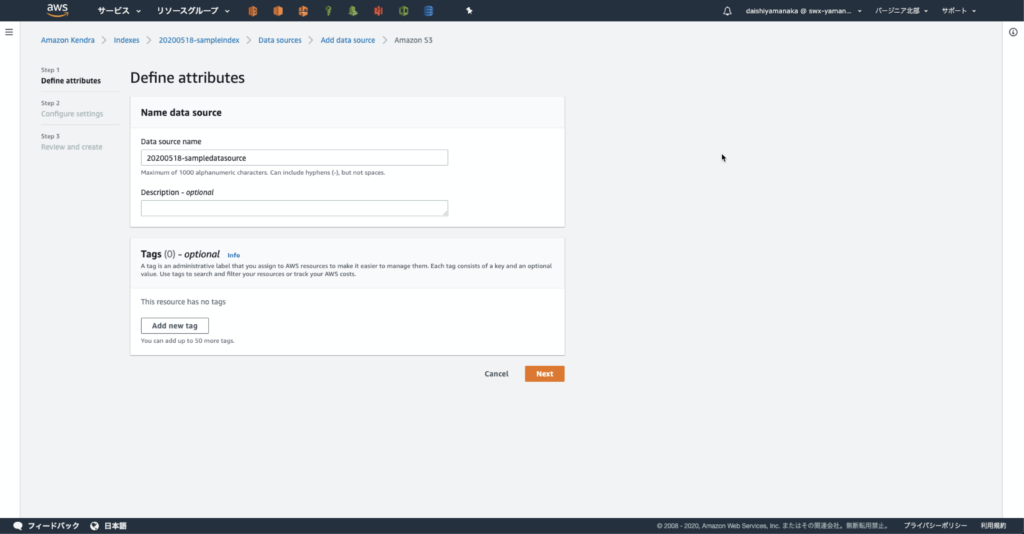
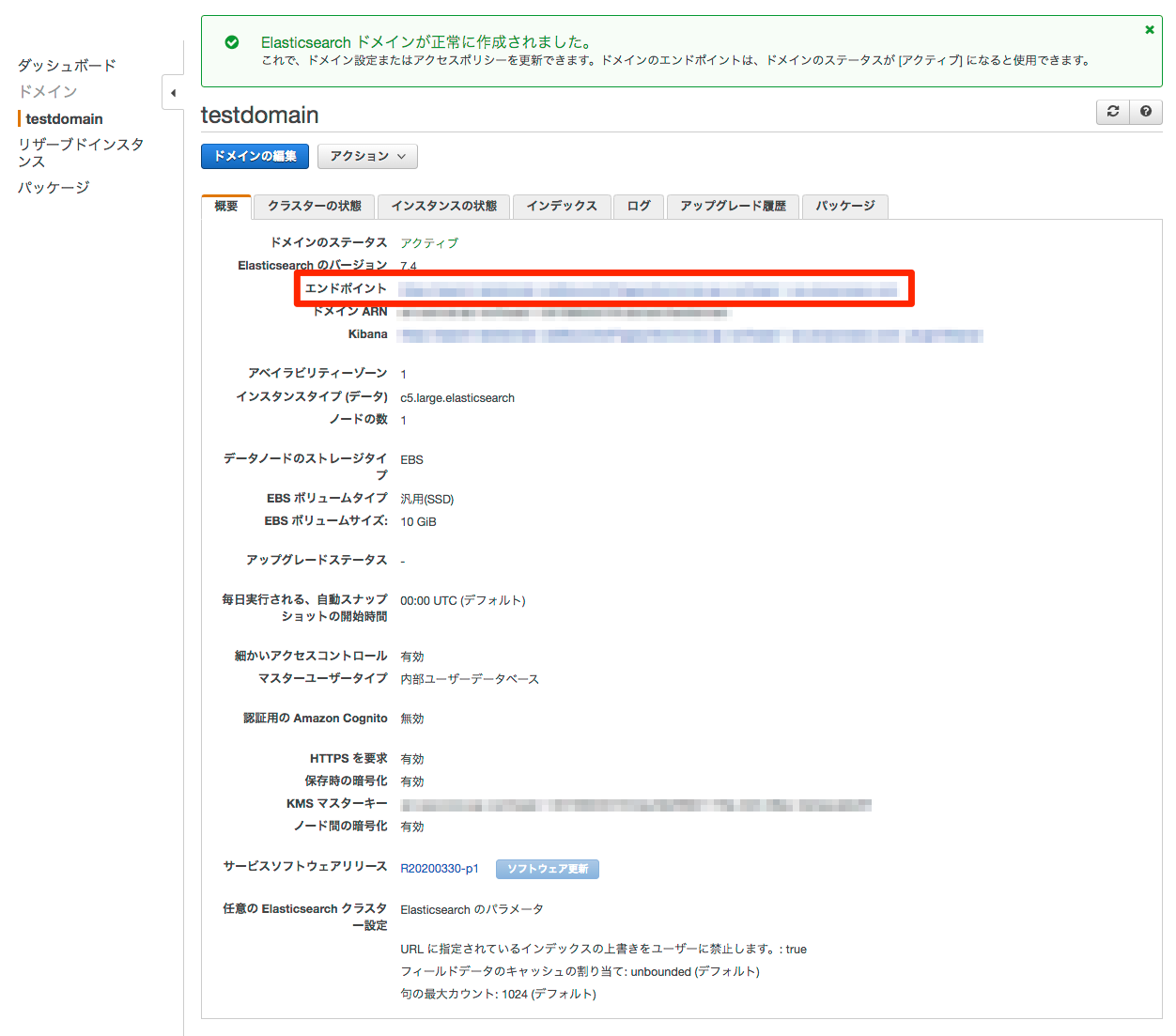
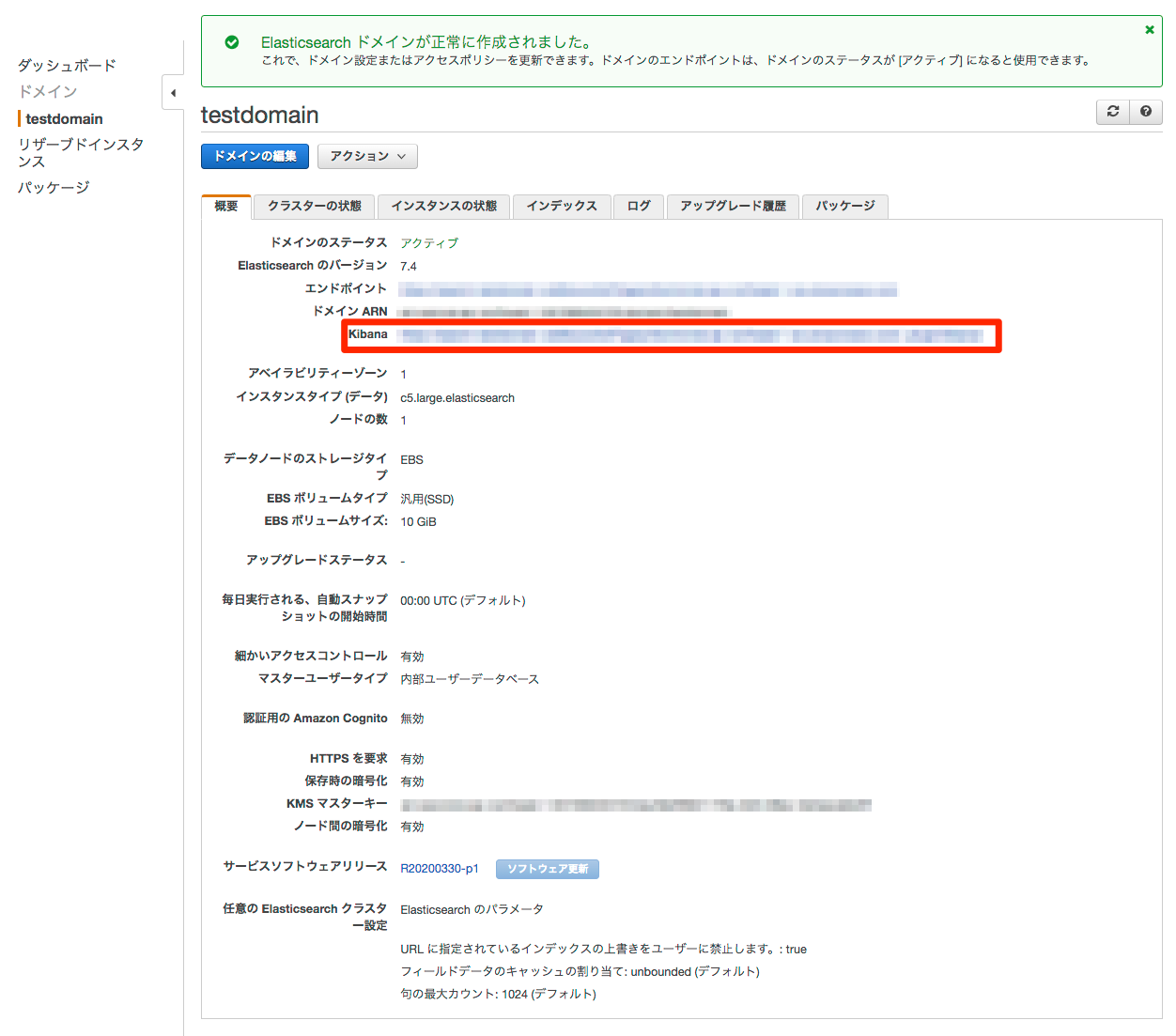
はじめに
こんにちは、技術1課の山中です。
ずっと最近は家に引きこもっていますが、家のネットが貧弱でとても辛いです。
そんな中、同僚から有線にしなよとアドバイスをもらいました。
面倒だし頑なに拒否していたのですが、一昨日くらいから試しに有線に変えてみて、すこぶる調子がよくなりました。
有線、よいです。
今回は IAM Access Analyzer のアップデートです。
IAM Access Analyzer はこれまでも S3 バケットについてはサポートしていたのですが、バケットに適用されているバケットポリシーと ACL についてのみの検出しかできませんでした。
今回のアップデートで新たに S3 アクセスポイントポリシーにも対応しました!!
このアップデートで、 アクセスポイントを使用する S3 バケットへの意図しないアクセスを見つけ、アクセスを許可するアクセスポイントを特定することが簡単にできるようになります。
S3 アクセスポイントを介して共有された S3 バケットへの意図しないアクセスを検出、確認、修正する
IAM Access Analyzer とは
IAM Access Analyzer は他の AWS アカウントや外部からアクセスされる可能性があるかどうかを検出する機能で、 AWS re:Invent 2019 にて発表されました。
S3 や IAM など外部に公開できるサービスのポリシーをチェックし、一覧化してくれます。
IAM Access Analyzer とは – AWS Identity and Access Management
IAM Access Analyzerで外部アクセスポリシーを検出しよう – サーバーワークスエンジニアブログ
検出した結果は Amazon EventBridge にて通知することも可能です。
Amazon EventBridge による AWS IAM Access Analyzer のモニタリング – AWS Identity and Access Management
IAM Access Analyzer は外部からアカウント内のリソースにアクセスがあったかどうかについては関知する訳ではありません。
あくまでもポリシーを根拠に判断するだけです。
※ IAM Access Analyzer はリージョンごとに有効化する必要があります。
サポートしているリソースタイプ
2020/05/12 現在、 IAM Access Analyzer がサポートしているリソースタイプは以下です。
- Amazon Simple Storage Service バケット
- AWS Identity and Access Management ロール
- AWS Key Management Service キー
- AWS Lambda の関数とレイヤー
- Amazon Simple Queue Service キュー
詳細は サポートされているリソースタイプ – AWS Identity and Access Management をご覧ください。
料金
IAM Access Analyzer は 追加料金なし でご利用いただけます。
試してみる
早速、 S3 アクセスポイントポリシーが IAM Access Analyzer でどのように検出されるのか試していきましょう!
IAM Access Analyzer の有効化
事前に IAM Access Analyzer を有効化しておきます。
有効化の手順は以下のブログを参照してください。
IAM Access Analyzerで外部アクセスポリシーを検出しよう – サーバーワークスエンジニアブログ
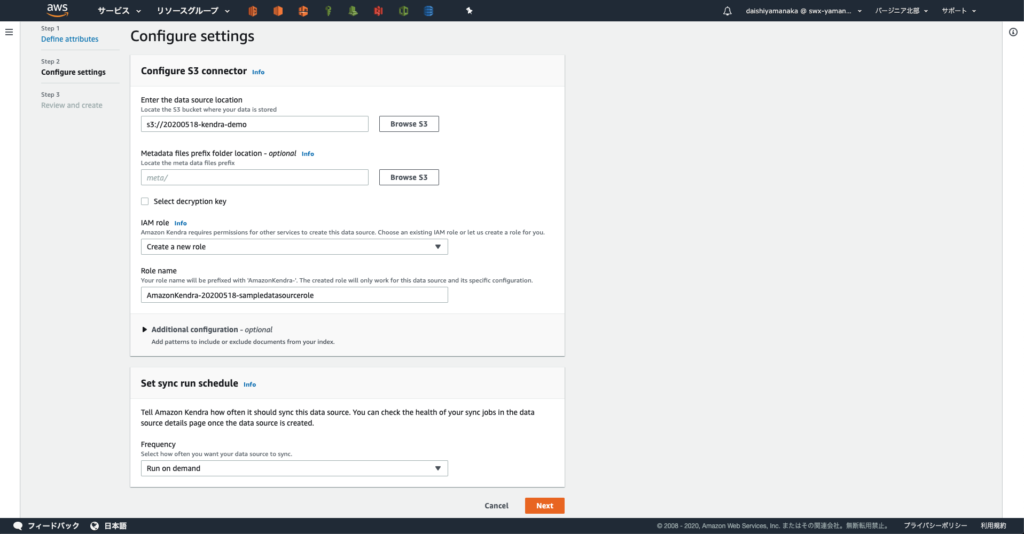
S3 バケットの用意
自分の AWS アカウント 111111111111の S3 バケットに S3 アクセスポイント経由で他の AWS アカウント 222222222222 からアクセスできるように S3 バケットを用意していきます。
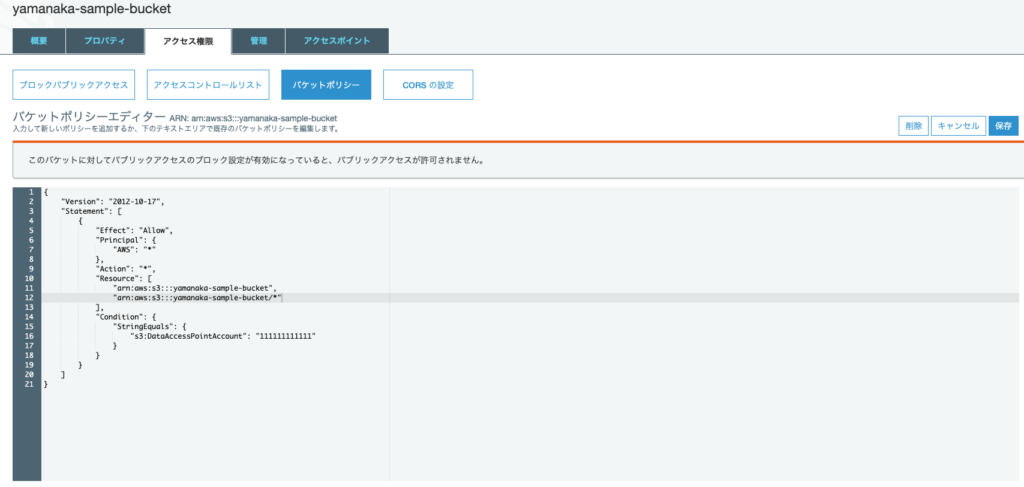
適当な名前 yamanaka-sample-bucketで S3 バケットを作成したら、アクセスポイントへのアクセスコントロールの委任 に従いバケットポリシーを更新し S3 アクセスポイント経由でのみバケットにアクセスを許可するようにします。
アクセス権限 タブの バケットポリシー に以下を記載し保存します。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "*"
},
"Action": "*",
"Resource": [
"arn:aws:s3:::yamanaka-sample-bucket",
"arn:aws:s3:::yamanaka-sample-bucket/*"
],
"Condition": {
"StringEquals": {
"s3:DataAccessPointAccount": "111111111111"
}
}
}
]
}
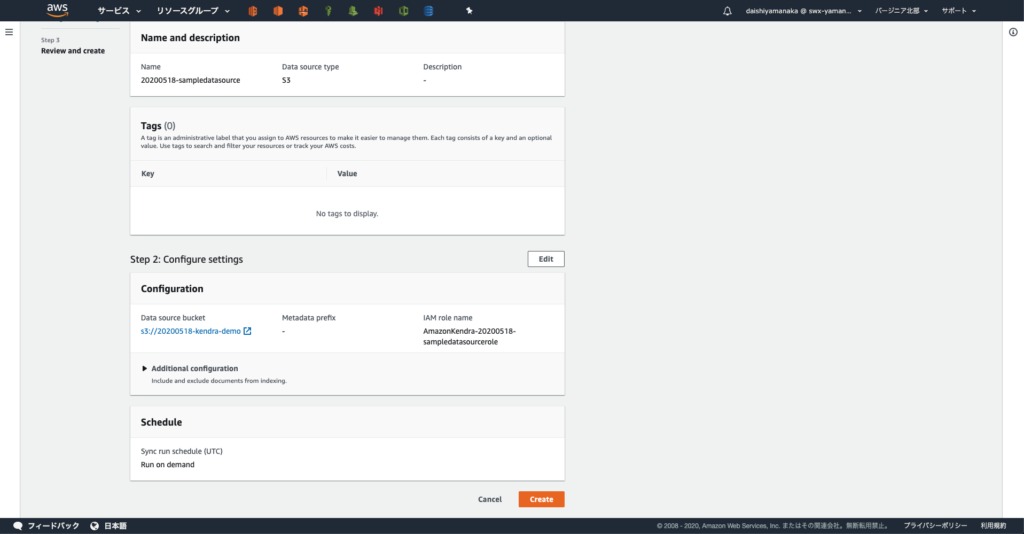
続いて S3 アクセスポイントを作成します。
アクセスポイント タブにて アクセスポイントを作成 ボタンをクリックします。
アクセスポイント名 を適当に入力後、 ネットワークのアクセスタイプ で インターネット を選択します。
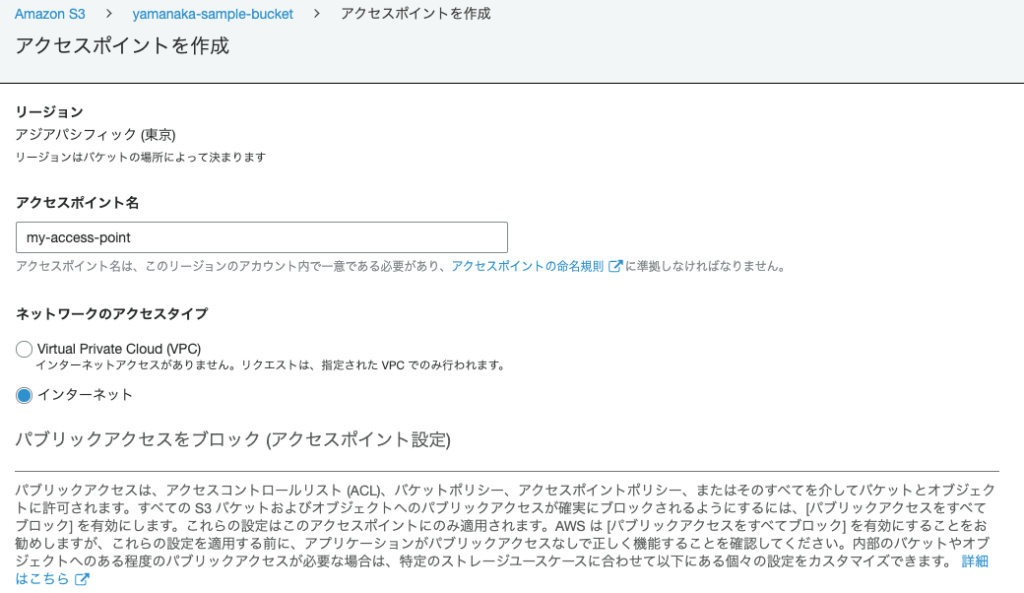
パブリックアクセスをブロック (アクセスポイント設定) では パブリックアクセスをすべてブロック のチェックを外してください。

今回はアカウント 222222222222 の IAM ユーザ daishiyamanakaに、 アクセスポイント my-access-pointを介して、 S3 バケットのオブジェクトに GETと PUTのアクセス許可を付与します。
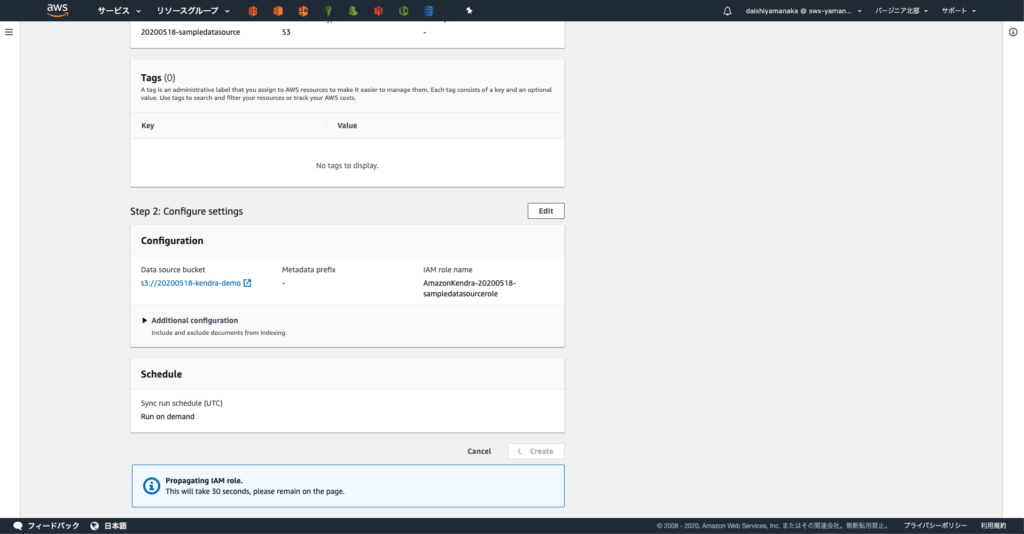
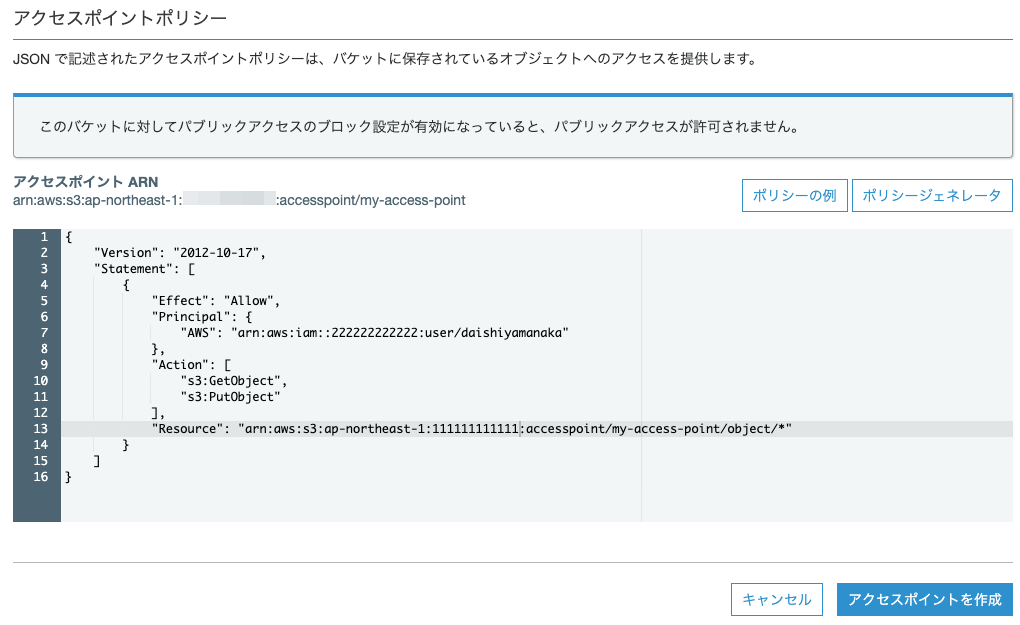
アクセスポイントポリシー に以下を貼り付け、 アクセスポイントを作成 ボタンをクリックします。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::222222222222:user/daishiyamanaka"
},
"Action": [
"s3:GetObject",
"s3:PutObject"
],
"Resource": "arn:aws:s3:ap-northeast-1:111111111111:accesspoint/my-access-point/object/*"
}
]
}
これで S3 バケットの用意は完了です。
試しにアカウント 222222222222にてアクセスキーを発行し、以下コマンドで画像をアップロードしてみたところ正常にアップロードされていました。
$ aws s3api put-object --bucket arn:aws:s3:ap-northeast-1:111111111111:accesspoint/my-access-point --key sample.jpeg --body sample.jpeg
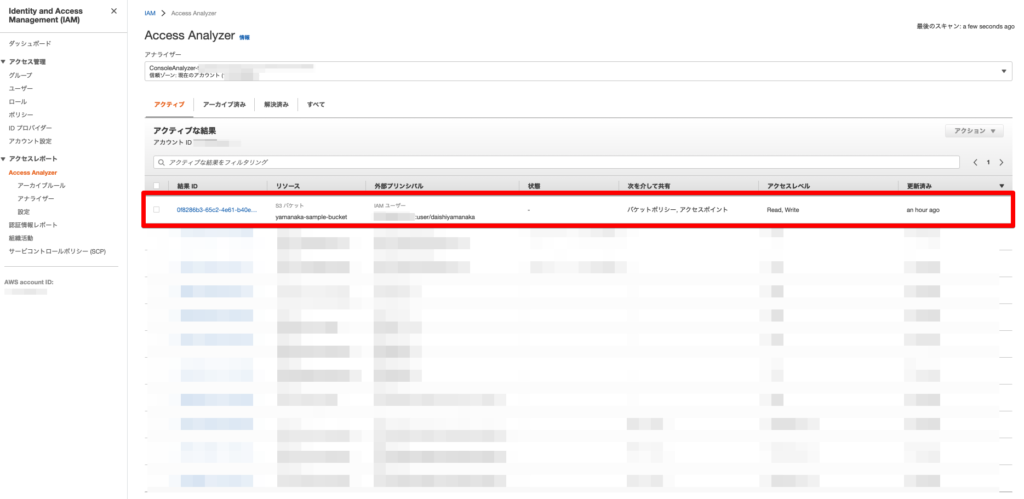
IAM Access Analyzer の確認
IAM Access Analyzer を確認してみましょう!!
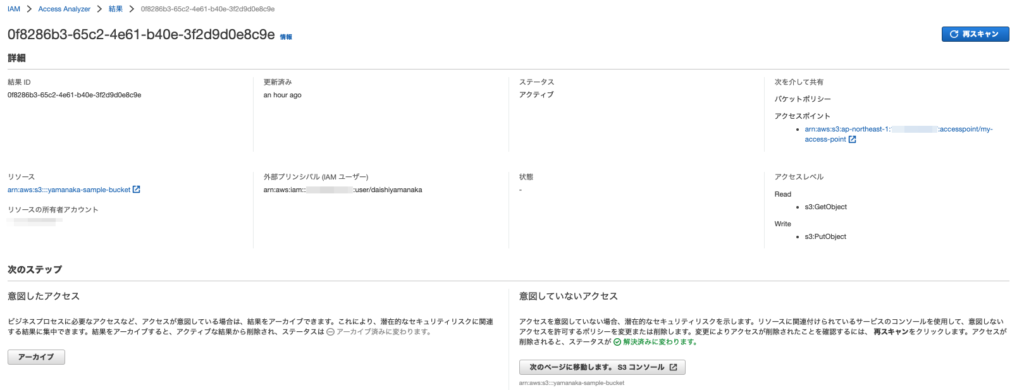
きちんと用意したバケットが検出されています!
対象レコードの 結果 ID をクリックして詳細を表示します。
次を介して共有 の項目にきちんとアクセスポイントが記載されていました!!!
おわりに
IAM Access Analyzer を使うと、外部からの予期せぬアクセスを未然に防ぐことができます。
無料で利用できますので是非、 AWS アカウントセットアップ時に有効化しておきましょう!!
また、この内容は 2020/5/13(水) 12:00 よりYouTube Liveで配信する「30分でわかる AWS UPDATE!」で取り上げます!
是非ご覧ください!