技術3課の島村です。
最近気温の落差が激しいですが、元気に体調も崩さず過ごしています。
皆様も体調管理は気をつけましょうね。
さて、今回はAppStream2.0を構築していきます。
その前にAppStream2.0ってどんなサービスなのか知ってもらうために
サービスの特徴を箇条書きにしてみました。
AppStream2.0とは
・完全マネージド型のアプリケーションストリーミングサービス
・アプリケーションの集中管理
・ActiveDirectoryと連携可能
・アプリケーションとデータの保護
より詳細な機能を知りたい方はAWS公式ページをご確認ください。
https://aws.amazon.com/jp/appstream2/
やること
さて、簡単にサービスの特徴を書いたところで、今回の記事の中でやることを書きました。
以下の通りです。
1.Image Builderの作成
2.Imageの作成
3.Fleetの作成
4.Stackの作成
5.ユーザーの作成
6.ストリーミング配信を体験してみる
…項目多いですね。
今回は構築手順を中心に扱っています。
各コンポーネントの説明と設定値の説明については一部割愛しています。
構築する前にVPC、SecurityGroupを事前に作成しておいてください。
それでは早速始めていきます。
1.Image Builderの作成
まずはImage Builderを作成していきます。
AppStream2.0のメニューから[Images]→[Image builder]タブから
[Launch Image Builder]を選択します。
![]()
元となるイメージを選択します。
描画性を求められるアプリケーションなど、アプリケーションの要件によって
求められるインスタンスファミリーがあると思います。
イメージ選択についても考慮する必要があります。
今回はあくまで動作を確認するためだけなので
[AppStream-WinServer2012R2-05-28-2019]というイメージを選択します。
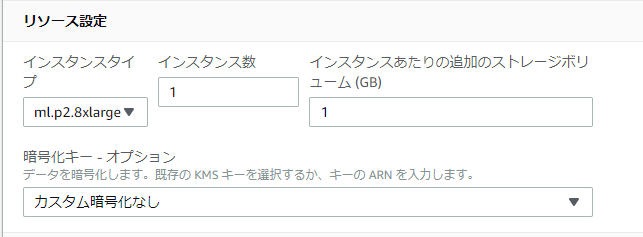
Image Builder名と任意のインスタンスタイプを選択して[Next]を選択します。
![]()
Image Builderを配置する[VPC]、[サブネット]、[SecurityGroup]を選択します。
![]()
設定のレビューです。よければ[Lunch]を選択してImageBuilderを作成します。
![]()
作成後、Image Builderに接続できるようになるまで10分~15分程度かかります。
コーヒーでも飲んで気長に待ちましょう。
2.Imageの作成
コーヒーブレイクは楽しめたでしょうか?
さて、ここからはImageを作成していきます。
Image Builderの[Status]が[Running]になったら接続できるようになります。
接続したImage Builderを選択して、[Connect]を押して接続しましょう。
![]()
接続するとどのアカウントでログインするか求められます。
各アカウントごとの役割は以下の通りです。
| Administrator |
アプリケーションのインストール、アプリケーションカタログの作成 |
| Template User |
デフォルトとなるアプリケーション設定とWindowsOS設定/保存を行う |
| Test User |
インストールしたアプリケーションの起動確認
Windows設定の確認用 |
最初にアプリケーションのインストールを行う必要があるので
[Administrator]を選択します。
![]()
[Administrator]でログインできたら必要なアプリケーションを
インターネットやインストーラ等を使用してインストールしてください。
今回はインターネットからアプリケーションをインストールせずに、Windowsに
もともと入っているアプリケーション(メモ帳、エクスプローラー、IE)でカタログを作っていきます。
アプリケーションカタログを作成するにはDesktopにある[Image Assistant]を選択して
起動します。
![]()
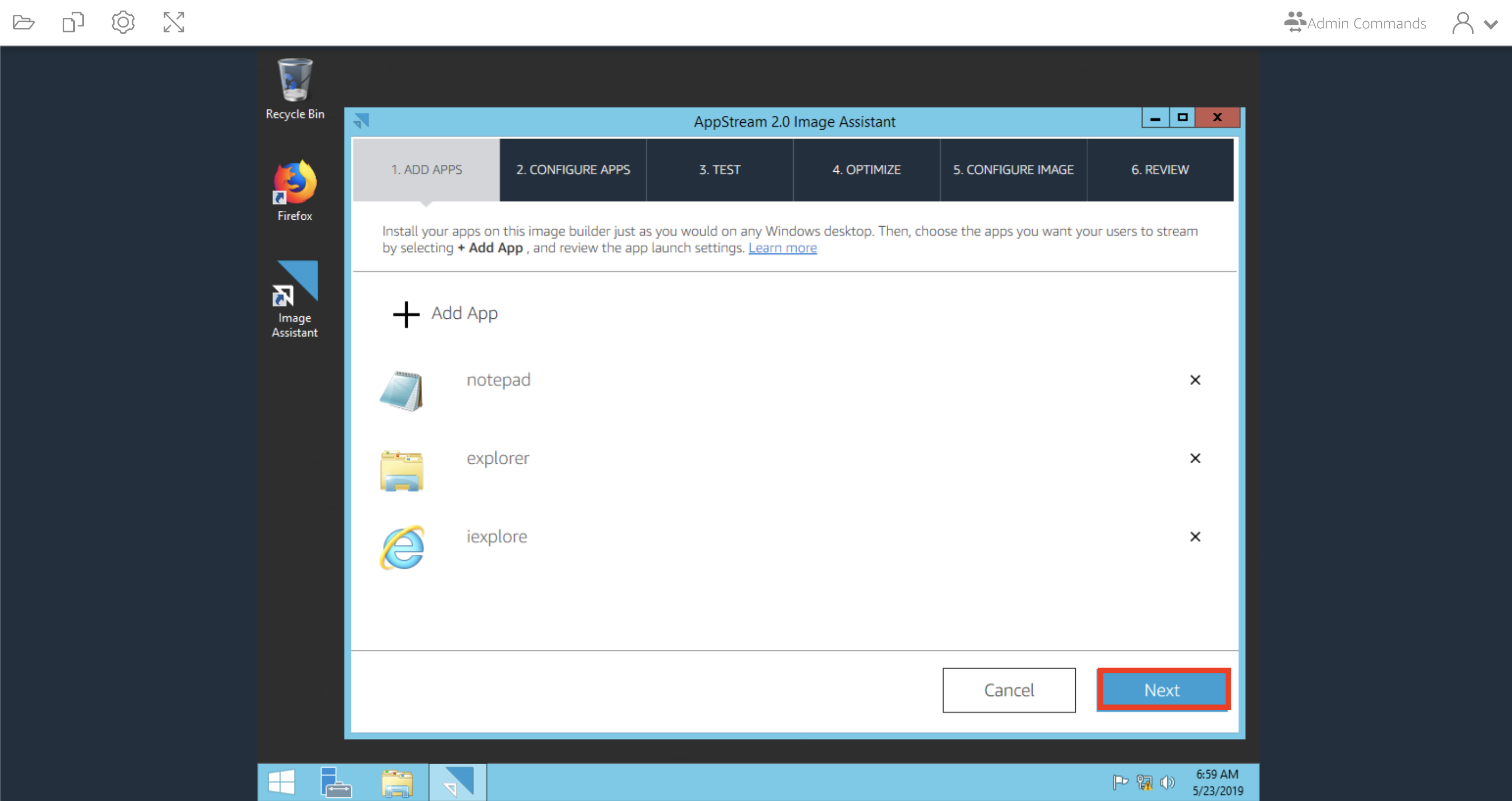
[Image Assistant]を起動するとアプリケーションカタログに追加するアプリケーションを
追加する画面が表示されます。[+ Add App]を選択してアプリケーションを選択します。
![]()
今回はWindows OSでおなじみのアプリケーションをカタログに追加しました。
追加したら[Next]を押して次に進みます。
![]()
ユーザー共通のアプリケーションの設定やWindowsの設定がある場合は、
[Switch User]を選択して[Template User]に切り替える必要があります。
今回は特にそういった設定は行わないためスキップします。
ちなみに[Template User]で設定が完了後、再度[Administrator]に切り替え
[Save Setting]を押すことで始めて設定が保存されますのでご注意ください。
設定が終わったら、[Next]を選択します。
![]()
ここでは[TEST User]を使用してアプリケーションカタログで選択しているアプリケーションが
正常に起動するか確認します。[Switch User]を選択して[Test User]に切り替えることができます。
![]()
アプリケーションの動作確認とWindowsの設定が確認できたら
Userを[Administrator]に切り替えます。
![]()
右上の[AdminCommands]から[Switch User]を選択します。
Administratorに切り替えるとImageAssistantが[OPTIMIZE]に進みます。
![]()
ここではアプリケーションの起動について依存関係がないかを確認し、
最適化を行うステップです。[Launch]を選択してアプリケーションを起動します。
アプリケーションの起動に問題なければ、[Next]を選択します。
![]()
![]()
ここではイメージ名とイメージの説明を入力します。適当なイメージ名を入力しましょう。
![]()
最後にイメージ名と説明を確認して[Disconnect and Create Image]を押します。
押した後、イメージビルダーとの接続が切れますが問題ありませんので安心してください。
これでイメージの作成は完了です。
イメージの作成までに20〜25分程度かかります。
2回目のコーヒーブレイクを楽しみましょう。
3.Fleetの作成
2回目のコーヒーブレイクは楽しめたでしょうか?
楽しめた方はなかなかのカフェイン中毒ですね。
さて、次はFleetを作成していきます。この調子でどんどん行きましょう!
左ペインから[Fleet]を選択し、[Create Fleet]から作成していきます。
![]()
Fleet名、Fleetの説明を入力します。
![]()
Fleetで使用するイメージを選択します。今回は先ほど作成したイメージを選択しましょう。
![]()
次にFleetの設定を行なっていきます。
以下の項目について設定が可能です。
・インスタンスタイプ
・フリートタイプ
・セッションの設定
・フリートスケーリング
今回の構築では設定値を以下の通りで設定しています。
| インスタンスタイプ |
フリートタイプ |
セッションの設定 |
フリートスケーリング |
| Stream.standard.medium |
On-demand |
デフォルト |
デフォルト |
設定したら[Next]を押します。
![]()
ネットワーク周りの設定を行います。
配置するVPC、サブネット、セキュリティグループを選択したら[Next]を押して次へいきます。
![]()
確認して問題なければ[Create]を選択します。
![]()
Fleetが完成しました。
Fleetは起動までに10分程度かかります。この間にStackの作成を行いましょう。
![]()
4.Stackの作成
さぁ、ここまできたら残りはあと少しです。頑張っていきましょう!!
左ペインから[Stack]を選択して、[Create Stack]から作成を行います。
![]()
Stackの基本設定を行なっていきます。
ここではStack名の入力と、関連させるFleetを選択します。
選択し終えたら[Next]を押して次に進みます。
![]()
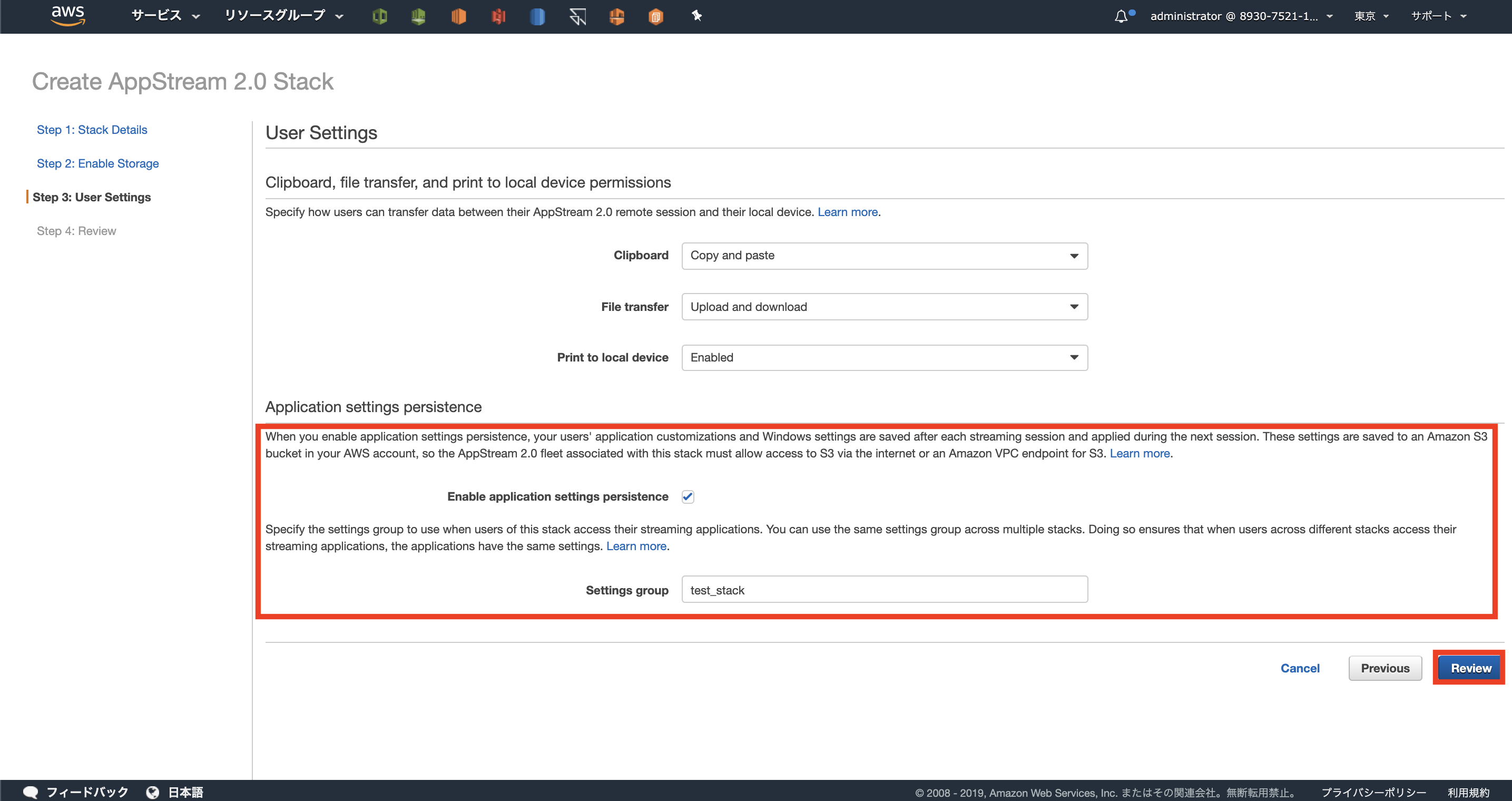
ストレージ設定を行います。
[Home Folder]、[GoogleDrive for G suite]、[OneDrive for Bisiness]が選択できます。
ここでは[HomeFolder]のみにチェックを入れます。
![]()
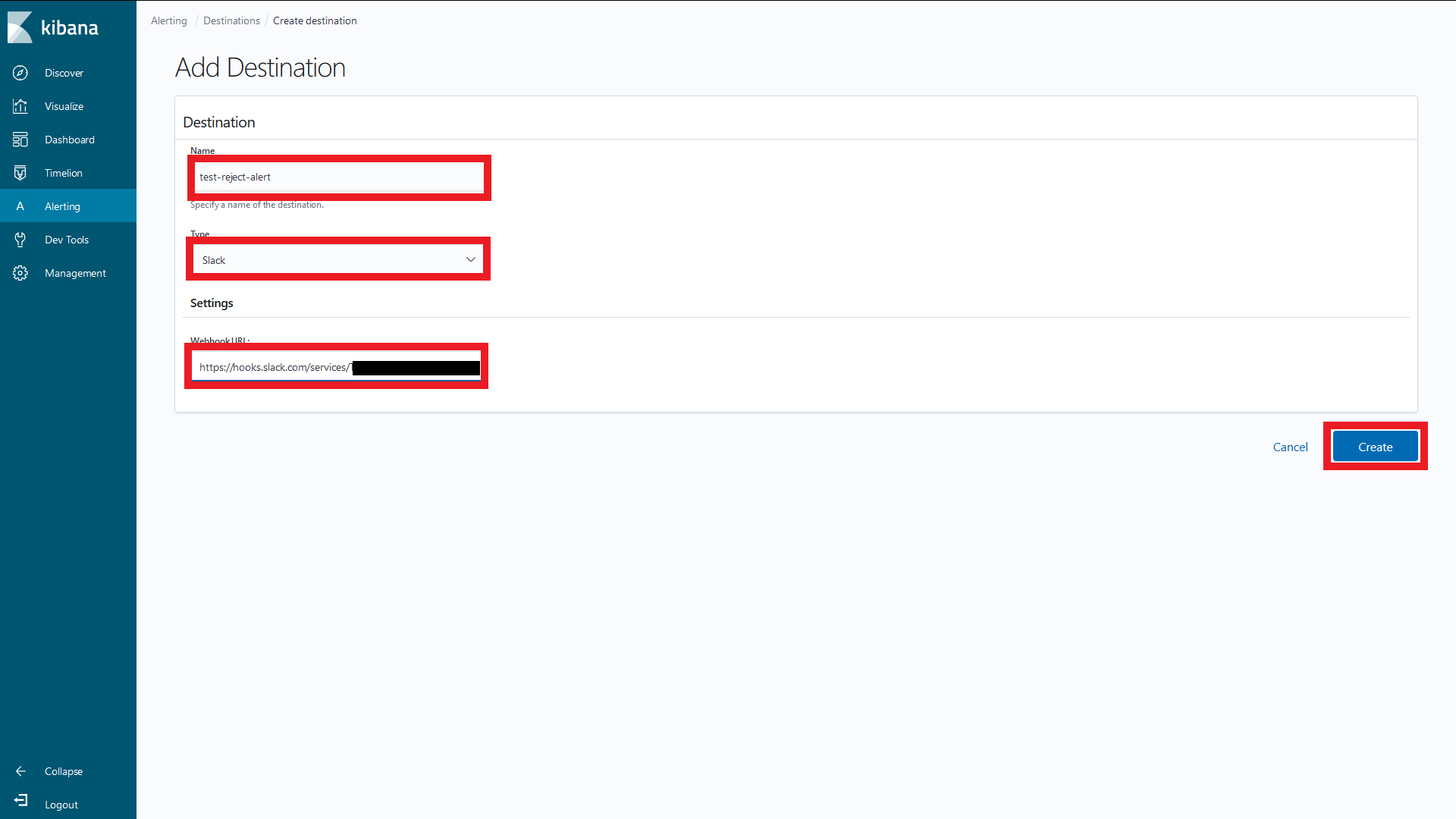
ユーザーのクリップボード有効化、アプリケーション設定の永続化、ローカルデバイスとの
ファイル転送について設定することができます。
[Enable Application Persistence]にチェックがついてなければつけてください。
その他の設定についてはデフォルトのままでOKです。
![]()
内容を確認して問題なければ作成します。
![]()
これでStackの作成は完了です。
5.ユーザーの作成
ユーザーの作成をしていきます。
左ペインから[User Pool]→[Create User]を作成します。
![]()
選択すると招待するユーザー名とメールアドレスを入力するポップアップが出てきます。
招待したいユーザー名とメールアドレスを入力しますが、今回は自分自身のメールアドレスを
入力します。
![]()
入力が完了するとメールアドレスが送信されます。
送付されたメールを確認する前にユーザーと作成したStackを紐付ける必要があります。
作成したユーザーを選択した状態で[Action]ペインを開き、[Assign Stack]押します。
選択後にポップアップが表示されるので、ユーザーに関連付けたいStackを選択します。
![]()
これでユーザーの準備が整いました!!!
6.アプリケーション配信環境を体験する
前の章で送られてきたメールを確認します。
ログイン画面へのリンクがあるのでアクセスします。
![]()
アクセスするとメールアドレスとパスワードを求められるので入力していきます。
※送付されたメールに初期パスワードが書いてあります。
![]()
入力すると初期パスワードを変更するよう求められるので、任意のパスワードに変えていきます。
パスワード変更が終わったら再びメールアドレスとパスワード情報を入力します。
ログインできるとアプリケーションカタログが表示されます。
![]()
どのアプリケーションでもいいので選択するとストリーミング接続が開始されます。
![]()
そしてついに….
![]()
接続できました!!!!!ここまで長かったですね!!!!
最後に
長い記事となってしまいましたがこれでAppStream2.0の環境が構築できたと思います。
比較的簡単にアプリケーションの配信と集中管理できるのは魅力的ですね。
次回はAppStream2.0とActiveDirectoryを連携させる手順を記事にしていきたいと思います。










































 こんにちは、AWSセールスエンジニアの加藤カズキです。週末は近所のホームセンターは赴いて草花を買い、自宅に植えるのが楽しみです。
こんにちは、AWSセールスエンジニアの加藤カズキです。週末は近所のホームセンターは赴いて草花を買い、自宅に植えるのが楽しみです。




























































 今回と前回の更新を踏まえ、各AZの特徴を再度まとめてみましょう。
今回と前回の更新を踏まえ、各AZの特徴を再度まとめてみましょう。