あ〜た〜らし〜い、朝が〜きた〜
おはようございます。技術1課の木次です。いっちに〜
皆さんラジオ体操してますか?さんし〜
今週1週間はリモートワーク勤務が推奨されています。(2019年もテレワーク・デイズに参加いたします)
ずーっと自宅だと体に悪いので、期間中はなるべくラジオ体操をやっています。いっちに〜 さんし〜
SFTP で AWS 側にファイル転送
古いシステムやパッケージ連携などで、ファイル転送に SFTP を利用するケースがあります。
SFTP とは SSH File Transfer Protocol の略で、文字通り SSH 経由でファイル転送をするため、従来の FTP に比べてセキュアな通信が可能です。
この SFTP で AWS 側にファイル転送する場合、EC2 インスタンスをたてて、というやり方もありますが、可用性を考えるとやりたくないですよね。
そのような場合、AWS Transfer for SFTP を利用すると幸せになれます。
AWS Transfer for SFTP
昨年の re:Invent 2018 で発表されたマネージドな SFTP サービスです。
転送したファイルは S3 に保存してくれるので、やろうと思えばサーバーレスな環境を構築できます。
気になる金額ですが、1時間ごとの料金になります。(それ以外にデータアップロードとダウンロードの転送料金も発生)
東京リージョンだと、1 時間あたり 0.3USD。常時稼働した場合、1日で 7.2 USD。1月だと約 216 USD です。
特定の時間だけ利用したい
いやー、ファイル転送するのは朝方だけなんだよねぇ。1時間だけでいいんだよ。
オンプレなら難しいですが、AWS なら 1時間だけ 大丈夫です。スケジュール実行した Lambda から AWS Transfer for SFTP を作成・削除してみましょう。
せっかくなので、ラジオ体操中にファイル転送を試してみます。いっちに〜 さんし〜
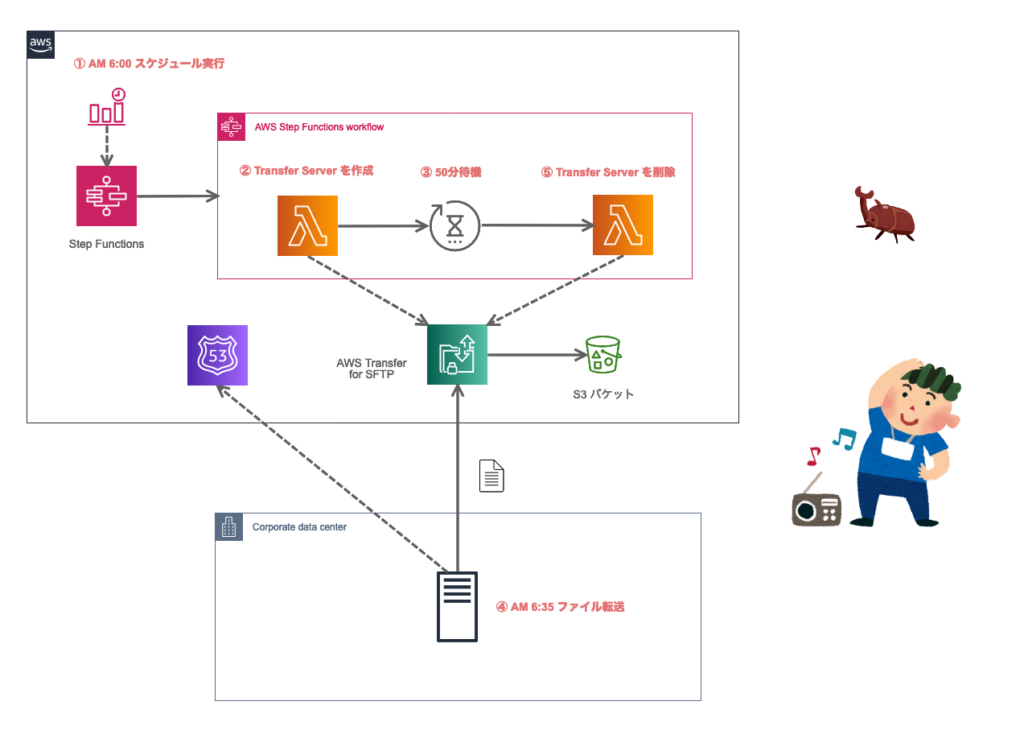
おおまかな流れは以下になります。
- 【CloudWatch】AM 6:00 スケジュール実行
- 【Step Functions】Transfer Server を作成
- 【Step Functions】50分待機
- 【クライアント】AM 06:35 ファイル転送
- 【Step Functions】Transfer Server を削除
ポイントは Step Functions。
2 で作成した Transfer Server のサーバーID をステートとして保持し、4 で削除のために利用します。
AWS Step Functions
AWS Step Functions は、視覚的なワークフローを使用して、分散アプリケーションとマイクロサービスのコンポーネントを調整できるマネージドなサービスです。ASL (Amazon States Language) と呼ばれる JSON 形式の言語でワークフローを定義できます。
このワークフロー内で、タスクを定義して Lambda を呼び出します。
Lambda 自身はステートレスなので状態(ステート) を保持できせん。ですが、Step Functions を利用すると、ワークフロー内で値を引き渡すことができます。
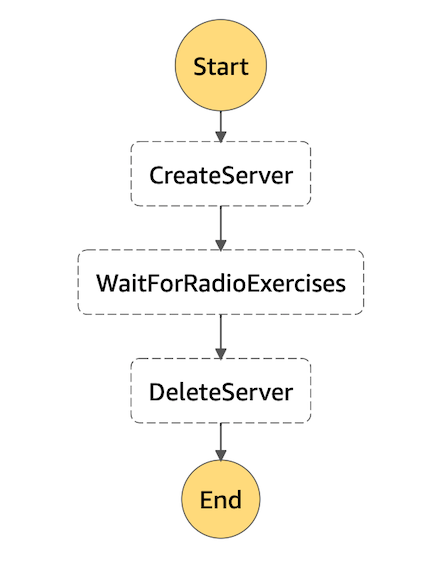
ワークフローを下記のように定義します。状態遷移はシンプルに上から下へ流れるだけです。
{
"StartAt": "CreateServer",
"States": {
"CreateServer": {
"Type": "Task",
"Resource": "arn:aws:states:::lambda:invoke",
"Parameters": {
"FunctionName": "arn:aws:lambda:ap-northeast-1:xxxxxxxxxxxx:function:create-transfer-server:$LATEST",
"Payload": {
"Input.$": "$"
}
},
"OutputPath": "$",
"Next": "WaitForRadioExercises"
},
"WaitForRadioExercises": {
"Type": "Wait",
"Seconds": 3000,
"Next": "DeleteServer"
},
"DeleteServer": {
"Type": "Task",
"Resource": "arn:aws:states:::lambda:invoke",
"Parameters": {
"FunctionName": "arn:aws:lambda:ap-northeast-1:xxxxxxxxxxxx:function:delete-transfer-server:$LATEST",
"Payload": {
"Input.$": "$"
}
},
"End": true
}
}
}
StartAt 項目では、最初に起動するステートを設定し、Next 項目で次に実行するステートを設定します。最後のステートには End 項目に true を設定します。
処理詳細
細かく見ていきましょう。
1. AM 6:00 スケジュール実行
CloudWatch Events で 日本時間 AM 6:00 (0 21 * * ? *) に起動するルールを作成します。UTCなので、そこは注意です。
起動するターゲットとして作成した Step Functions ステートマシン を選択し、入力値として 定数(JSON) を渡します。
{
"HostedZoneId": "Route53 ホストゾーンID",
"UserName": "SFTPユーザー名",
"UserRoleArn": "arn:aws:iam::xxxxxxxxxxxx:role/SFTPユーザーロール名",
"UserDirectory": "S3バケット保存先",
"SubDomain": "サブドメイン",
"LoggingRoleArn": "arn:aws:iam::xxxxxxxxxxxx:role/CloudWatchログ用ロール名"
}
この入力値は Lambda 内で利用します。
2. Transfer Server を作成
CreateServer ステートでは、ステートタイプに Task を指定して Transfer Server を作成する Lambda を呼び出します。
Transfer は比較的新しいサービスのため、boto3 モジュールと一緒にデプロイしてください。
対応していない場合は [ERROR] UnknownServiceError: Unknown service: 'transfer' と表示されます。
import os
import boto3
transfer = boto3.client('transfer')
route53 = boto3.client('route53')
def create_server(logging_role_arn):
response = transfer.create_server(
EndpointType='PUBLIC',
IdentityProviderType='SERVICE_MANAGED',
LoggingRole=logging_role_arn
)
return response.get('ServerId')
def upsert_cname_record(hosted_zone_id, server_id, sub_domain):
res1 = route53.get_hosted_zone(
Id=hosted_zone_id
)
host_name = res1['HostedZone']['Name']
record = sub_domain + '.' + host_name
region_name = boto3.session.Session().region_name
target = f'{server_id}.server.transfer.{region_name}.amazonaws.com'
res2 = route53.change_resource_record_sets(
HostedZoneId=hosted_zone_id,
ChangeBatch={
'Comment': f'{record} -> {target}',
'Changes': [
{
'Action': 'UPSERT',
'ResourceRecordSet': {
'Name': record,
'Type': 'CNAME',
'TTL': 300,
'ResourceRecords': [
{
'Value': target
}
]
}
}
]
}
)
return res2
def lambda_handler(event, context):
logging_role_arn = event['Input']['LoggingRoleArn']
hosted_zone_id = event['Input']['HostedZoneId']
sub_domain = event['Input']['SubDomain']
user_name = event['Input']['UserName']
user_role_arn = event['Input']['UserRoleArn']
user_directory = event['Input']['UserDirectory']
ssh_pub_key = os.environ['SSH_PUB_KEY']
# サーバー作成
server_id = create_server(logging_role_arn)
# CNAMEレコード作成
upsert_cname_record(hosted_zone_id, server_id, sub_domain)
# ユーザー作成
transfer.create_user(
ServerId=server_id,
UserName=user_name,
Role=user_role_arn,
HomeDirectory=user_directory,
SshPublicKeyBody=ssh_pub_key
)
return {
'Transfer': {
'ServerId': server_id,
'HostedZoneId': hosted_zone_id,
'SubDomain': sub_domain
}
}
- create_server
- SFTP サーバーを作成します。戻り値のサーバーID は削除時にも利用します。
- CloudWatch Logs にログ保存するためのロールを指定します。
- upsert_cname_record
- クライアント側からのエンドポイントを固定するため、CNAME レコードセットを作成します。
- 事前に Route 53 にホストゾーンを作成しておきます。
- create_user
- クライアントから接続するために、SFTP にユーザーを作成します。
- サンプルのため SSH 公開鍵は環境変数から取得しています。実際には SSM パラメータストア や Secrets Manager を検討した方がいいでしょう。
3. 50分待機
ステートタイプに Wait を指定して、待機する秒数を設定しています。
4. AM 06:35 ファイル転送
他サーバーに sftp を 実行するシェルを用意して、AM 6:35 (35 21 * * *) に実行されるように cron を仕掛けます。
#!/bin/bash sftp -i 秘密鍵 -o 'StrictHostKeyChecking no' -oPort=22 -b バッチファイル ユーザー名@ホスト名 exit 0
バッチファイルの中身では PUT コマンドを記述します。
5. Transfer Server を削除
import boto3
transfer = boto3.client('transfer')
route53 = boto3.client('route53')
def delete_server(server_id):
response = transfer.delete_server(
ServerId=server_id
)
return response
def delete_cname_record(hosted_zone_id, server_id, sub_domain):
res1 = route53.get_hosted_zone(
Id=hosted_zone_id
)
host_name = res1['HostedZone']['Name']
print(host_name)
record = sub_domain + '.' + host_name
region_name = boto3.session.Session().region_name
target = f'{server_id}.server.transfer.{region_name}.amazonaws.com'
res2 = route53.change_resource_record_sets(
HostedZoneId=hosted_zone_id,
ChangeBatch={
'Changes': [
{
'Action': 'DELETE',
'ResourceRecordSet': {
'Name': record,
'Type': 'CNAME',
'TTL': 300,
'ResourceRecords': [
{
'Value': target
}
]
}
}
]
}
)
return res2
def lambda_handler(event, context):
args = event['Input']['Payload']['Transfer']
server_id = args.get('ServerId')
hosted_zone_id = args.get('HostedZoneId')
sub_domain = args.get('SubDomain')
# サーバー削除
delete_server(server_id)
# レコードセット削除
delete_cname_record(hosted_zone_id, server_id, sub_domain)
- delete_server
- SFTP サーバーを削除します。作成したユーザーも一緒に削除されます。
- delete_cname_record
- 作成した CNAME のレコードセットを削除します。
実際にラジオ体操やってきた
ということで、ラジオ体操をやっている公園にやってきました。自宅から徒歩30分くらい。程よい距離で散歩にも適しています。
ラジオ体操は 6:30 スタート。
最初は第一体操から始まり、第二体操へ。そして40分頃に終了となります。
1日目

恥ずかしくて端っこから参加。
おいおい結構しんどいぞ、汗だらだら。そしてラジオ体操第二をすっかり忘れてる。。。
2日目

勇気を出して輪の中へ。いつか、あの真ん中のステージに立ちたい。いっちに〜 さんし〜
3日目

より前進。
3日目には恥ずかしさはなくなり、第二体操も8割くらい出来るように。気持ちいい〜。いっちに〜 さんし〜
結果は
さて、ファイルは届いているでしょうか。まずは Step Functions ワークフローの結果を確認します。
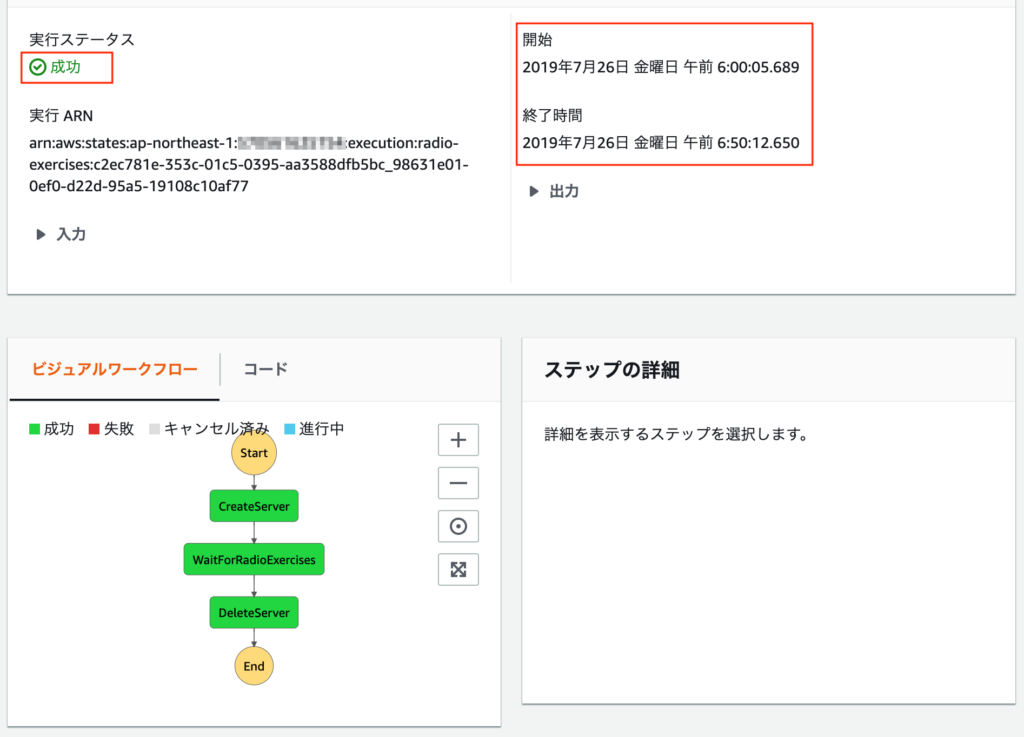
実行ステータスは成功 。開始と終了時間も想定通りです。
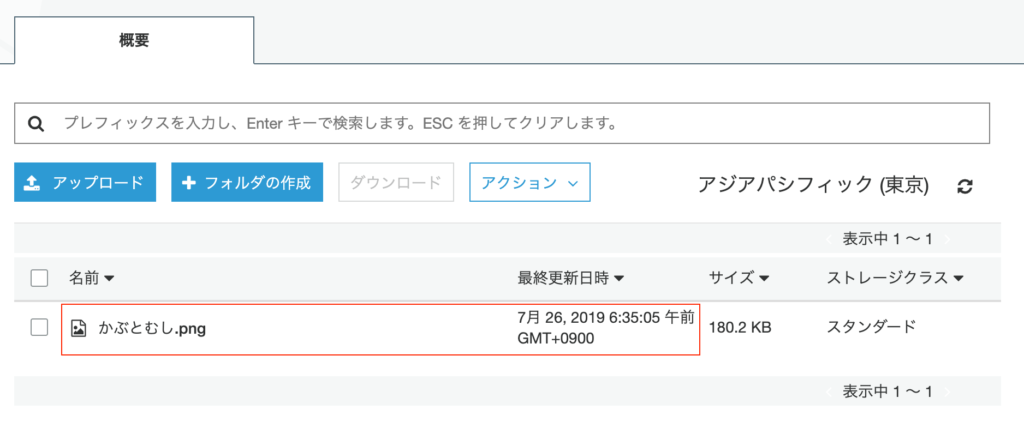
指定した S3 バケットにファイルが届いていました。更新日時も想定通りです。
やったね。
最後に
ラジオ体操はテレワーク・デイズ期間だけと思っていましたが、体と脳が刺激されて、その後の仕事がはかどるような気がしました。
せっかくなので、リモートワークの日は積極的に行こうと思います。
今日はこのへんで失礼します。いっちに〜 さんし〜


















 以下のとおり、
以下のとおり、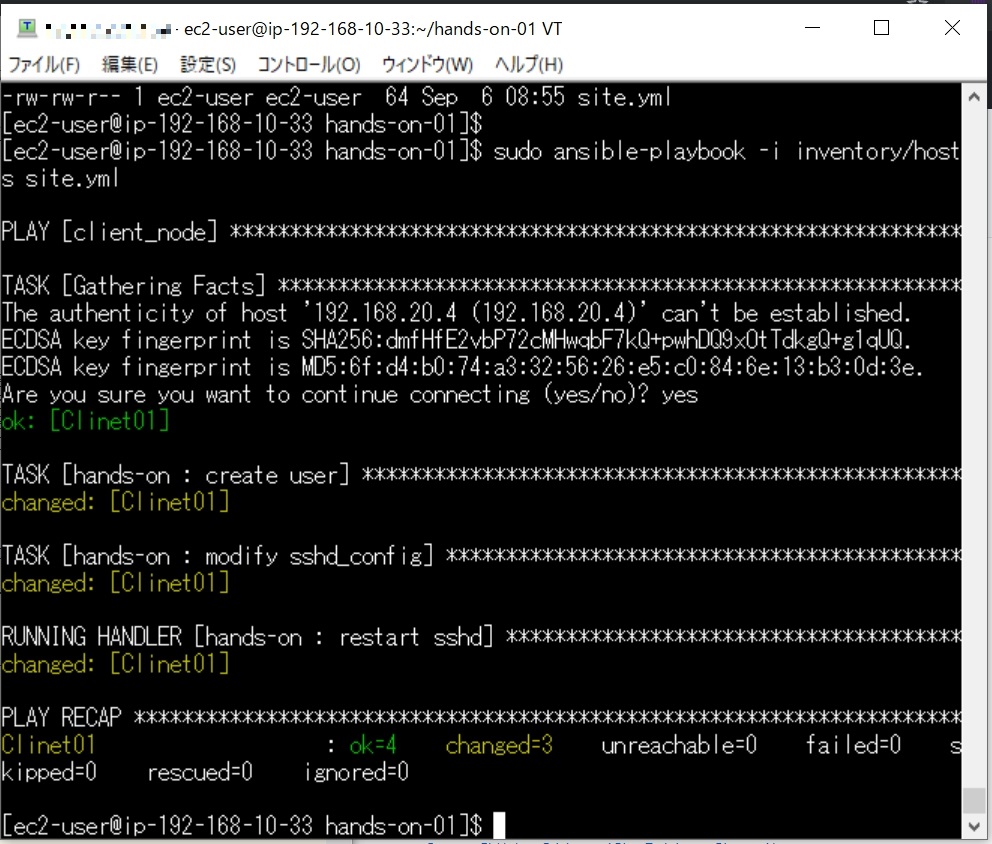 このPlaybookでは、Client01にパスワード認証でログインするユーザーを作成しました。
このPlaybookでは、Client01にパスワード認証でログインするユーザーを作成しました。 まずはインベントリファイルから作成。
まずはインベントリファイルから作成。