技術2課のタムラです。
日本のとある場所では最高40度だとかを記録しているような茹だるような猛暑の中
とあるお客様と一緒にSnowball Edgeを利用したシステムのデータ移行を実施してきました。
いわゆる「真夏の雪遊び」ってやつです。
ありがたい事に今回、お客様にご協力頂けましたので実際の作業の流れやら物理機器の様子など
Snowball Edgeを利用したデータ移行の一連の流れの雰囲気やら注意点をblogでお伝えできればと思います。
Snowball Edgeとは、Snowballの機能拡張版です。
Snowballと Snowball Edgeの違いは以下URIに綺麗にまとまっているので興味があれば確認してください。
https://docs.aws.amazon.com/ja_jp/snowball/latest/ug/device-differences.html
Snowball Edgeは、Snowballと違い筐体中にコンピューティングの機能を持ち
処理負荷の高いデータ暗号化処理等をSnowball Edge本体のリソースにて実施することができます。
従ってデータ移行を計画し、移行環境を整える必要があるユーザ側の視点だと
Snowballの場合は、Clientにかなりパワフルなスペックやら台数が要求される場合があるが
Snowball Edgeの場合は、Clientにそれほどのスペックは要求されない(*1)というのが
一番抑えておきたいポイントだと思います。
*1…ただしスペックは高いに越した事はない(後述)
また別途費用はかかりますが、Snowball Edgeの中でEC2をローンチして仮想サーバーを動かすというな事もでき、そのEC2インスタンスを Snowball Edge Clientとして利用する事も可能です。持ち運び可能なAWSのデータセンターみたいな感じですね。
詳細については最新のBlackbeltを参照頂くのが良いと思われます。
今回のデータ移行計画について
オンプレミス環境のシステムで利用されていた約30TBのアーカイブデータが今回の移行対象でした。
オンプレミスのサーバーはAWSへ移行し退役済みですが、アーカイブデータだけ物理のNAS装置に残された状態で、それらをS3へ速やかに移行するというのが今回のミッションでした。
本番で利用されているネットワークを利用したオンラインでの移行も検討しましたが、やはりテラバイトクラスのデータを他業務に影響が出ないよう帯域制御をかけながら細々とやるとなるとなると完了まで数年とか平気で要してしまうような状況であった事と、お客様にてパワフルなClient PCを用意することが難しかった事もあり、サーバーワークスとして今回Snowball Edgeを活用したデータ移行を提案しました。
データ移行環境の構成について
今回構築したデータ移行環境のイメージ図は以下です。
![]()
お客様の会社ポリシーでSnowball EdgeおよびClient PCのインターネット接続(遠隔操作)は、許可されない状況でしたので、データ移行を目的とした閉ざされたLAN環境となります。
朱書きの線は今回のデータ移行ではボトルネック(1GbE使い切り)となった箇所となり、もし用意可能であれば10GbEでの接続が好ましいと思われた箇所です。
データ移行元の対象機器は非ラックマウント型のQNAPのNAS装置*2で、現役時は社内のWindows Clientからネットワークドライブとしてエクスプローラー経由でデータ参照/更新の運用がされていたものでした。NAS装置(NASヘッド)が物理的に2つに分かれ、それぞれにUSB-HDD(一部USB2.0接続のためバスがボトルネックとなる)が容量拡張目的でぶら下がっているような構成でした。
移行元データの特徴
今回の移行元は業務システムで利用されていたアーカイブデータが主となり、数10MB-数GBのバイナリデータが多く1ファイルの平均サイズが大きめな点が特徴でした。
| データ容量 |
約30TB (30,228 GB) |
| ファイル数 |
1,731,346 |
| ディレクトリ数 |
48,873 |
| 1ファイル平均サイズ |
17.88 MB |
| 1ディレクトリあたりの平均ファイル数 |
35.43 |
Snowball Edgeのジョブ作成の前に
Snowball Edgeのジョブ作成へ進む前に実施した方が良い事前準備や調整事項について先に紹介します。
1.S3の仕様とデータ移行時の注意点の把握
S3はキーバリュー型のオブジェクトストレージでディレクトリ(=フォルダ)といった概念がありません。なのでもし移行元にいわゆる空ディレクトリのようなディレクトリ配下に何もファイルが存在しないものがあった場合、そのディレクトリはデータ移行されません。
もし、空ディレクトリのデータ移行がどうしても必要な場合は、例えばスクリプト等で空ディレクトリの配下にダミーファイルを作成する等、事前に考慮が必要となります。
もう一点、S3側の制約やら何らかの問題でデータ移行が失敗し、手動でのデータ移行が必要となる場合がある事を認識し、もし失敗した場合の対応方針についても検討しておく必要があります。
例えば、S3の禁則文字であれば以下URIの以下項目を参照
・特殊な処理を必要とする可能性がある文字
・使用しない方がよい文字
https://docs.aws.amazon.com/ja_jp/AmazonS3/latest/dev/UsingMetadata.html
2.データ移行先の S3 bucketの決定および作成
今回のようなデータ移行をする場合、ジョブ作成時に移行先の S3 bucketの指定が必要となりますので事前に検討および作成が必要です。
S3 bucketへのインポートする際の権限周りの設定は Snowball Edgeジョブ作成時に作成しますので単純にS3 bucketを作成するだけで問題ありません。
特別なポリシーでも無い限り、AWSによるインポートが完了するまではS3 bucketの設定はデフォルトからいじらない方が無難と思われます。
3.移行元のデータ傾向の分析
移行元のデータの傾向は、データ転送のパフォーマンスだけでなくClinetにも影響がありますので事前に分析しておく事は重要です。
ファイル数が大量かつ平均ファイルサイズがとても小さい傾向の場合、Client PC側でバッチ処理(tarで固めつつ転送する処理)を実施する事が推奨されます。
その為、ClientにパワフルなスペックのLinux OSの端末が必要となります。
(今回は平均サイズがかなり大きかったのと、Windowsのマシンしか調達出来なかった都合で Windows OSを利用し実施しました)
4.データ移行進捗の把握方法
Snowball Edge Clientを遠隔操作出来る場合はコマンドから確認する事ができますが、今回のように遠隔操作が許可されない環境の場合、データ移行進捗は現地で Snowball Edgeのフロントパネルに表示されているインジケータから進捗を確認し、想定残り時間等はユーザの方で算出するしかありません。
従ってSnowball Edge設置先での目視確認方法について考慮する必要があります。
5.課金体系とデータ移行所要時間の見積もり
201908時点で 100TBのSnowball Edgeの場合、リージョンによっても異なりますがジョブ作成(物理機器手配)で$300と、届いた翌日から10日間までは無料ですが11日目以降は一日あたり$30の課金が発生します。
料金の詳細は以下URIを参照
https://aws.amazon.com/jp/snowball-edge/pricing/
従って、Snowball Edgeを利用したデータ移行の計画を立てる場合は、コストの考慮をし不用意に長く機器を拘束してしまう事がないよう、過去事例などを参考に実環境でのデータインポートの想定時間を算出することが重要です。
今回は、Web上で公開されている他事例から今回の構成に近い内容を探し、同じ1Gbpsの環境でSnowball Edgeで AWS CLI(S3 Adapter経由)を利用して1GBを22secのレートで転送出来ていたとの情報を参考に推定所要時間の見積もりをしてから前に進みました。
| 22sec * 30,228GB = 665,016 sec = 11,083.6 min = 184.73 hours = 7.69 days |
(上の例では1ファイル1MBの例でしたので、今回の場合は1ファイルあたり平均17.88MBとかなり大きい事とNAS Headが2つでしたので倍ぐらい良いパフォーマンスが出る=1Gbps使い切れる可能性が高いと期待も添えておきましたが)
6.纏めますと
以下情報をきちんとお客様へ事前に説明し合意を得てからジョブ作成(機器手配)へと進むのがトラブルが少なく良いでしょう。
- S3の仕様や制約(空ディレクトリの取り扱い、禁則文字列等)について
- 何らかの原因で移行が失敗したデータの対応方針
- データ格納先のS3 bucketとデータの配置イメージ
- 移行元のデータ分析とその結果から用意すべきClient PCについて(傾向によってはLinux OS必須)
- データ移行進捗の確認方法 (遠隔操作可能であれば不要)
- Snowball Edge の11日目以降に発生する課金について
- データ移行環境での想定データ転送速度
- 想定データ転送速度が出た場合の想定データ移行所要時間
- 想定のパフォーマンスが出なかった場合のアクションプラン
Snowball Edgeジョブ作成
それでは実際に、Snowball Edgeのジョブ作成を行います。
「ジョブ」とはなんぞや?という話ですが、Snowball Edgeの機器手配からインポート完了までの一連の作業が1つの「ジョブ」として管理され、AWSマネージドコンソールでもステータスが可視化されます。実際に画面を眺めた方がイメージが伝わると思いますので続けて見ていきましょう。
I.AWSマネージドコンソソールから AWS Snowballの画面より ジョブの作成を押下
![]()
II.ジョブの計画を選択
今回はAWS(S3)へのデータ移行の為、「Amazon S3へのインポート」を選択します。
![]()
III.お届け先の情報を入力
Snowball Edgeの配送先住所を入力します。
![]()
IV.ジョブの詳細の入力
「ジョブ名」は、AWS管理者が管理しやすいお好きな名前を指定で問題ありません。
どのデータ移行の為のジョブなのかが明確となるよう案件名やらシステム名やらデータ移行プロ ジェクト名などを設定するのが一般的に良いと思われます。
![]()
V.インポートジョブのデバイスの選択
続けて同じ画面で、Snowballか Snowball Edgeか、はたまたCPUやGPUが強化された Snowball Edgeが選択できるので要件にあったデバイスを選択します。
VI.ストレージ
続けて同じ画面でデータ移行先の S3 bucketを選択します。
VII.セキュリティの設定
アクセス権限の箇所にて [IAMロールの作成/選択] を押下し、snowball-import-s3-only-role の利用を許可します。
(Snowball Edgeが当該アカウントのS3 bucketへのインポートする際に必要な権限を許可するイメージです)
![]()
[IAMロールの作成/選択]を押下後に以下を許可します。
![]()
VIII.暗号化
続けて、利用するデータ暗号化で利用するKMSキーを指定します。
特別な要件でもない限り、デフォルトのKMSキーで問題ないと思われます。
IX.通知の設定
Amazon SNSにてジョブステータス変更時にEmail通知を飛ばす設定を実施します。
![]()
Emailアドレスはカンマ等で区切り複数指定が可能です。今回はお客様とサーバーワークスの案件関係者を複数指定しました。
Subject:AWS Notification - Subscription Confirmation の Emailが指定した先に届くので Confirm subscriptionを実行すると以後、配送されたタイミングやインポート開始時等のジョブステータス変更時にEmailの通知を受け取ることができます。
X.最終確認画面にて内容を確認し、[ジョブの作成]を押下したら作業完了です。
(一応ジョブ作成から1h以内であれば料金発生せずにキャンセル可能です)
![]()
一連の作業の流れが下のインジケータで表現されており、Snowball Edgeが今どのようなステータスなのかをジョブダッシュボードから簡単に確認する事が出来ます。
あとはSnowball Edgeの機器が到着するまで待ちましょう。
Snowball Edge Clientの設定
Snowball Edgeの機器が到着するまで事前準備として、Client PCの環境を整備しておくと良いでしょう。今回利用した Client PCは以下スペックです。
(実は最初にお客様に用意頂いた機器でH/Wトラブルがあり急遽サーバーワークス内で余っていた代替機のノートPCを急遽手配しました)
| OS |
Windows10 Pro(64bit) |
| CPU |
Intel Core i3-7130U (2.70GHz 2133MHz 3MB) |
| MEM |
8.0GB |
| NIC |
1GbE |
A.Snowball Edge Clientの導入
以下からインストーラーを入手し導入します。
Windowsの場合は、コマンドプロンプトから snowballEdge コマンドを打てるようになればOKです。
https://aws.amazon.com/jp/snowball-edge/resources/
B.Pythonの導入
AWS CLIを導入する目的でPythonを導入します。
https://www.python.org/
C.AWS CLIの導入
AWS CLIを導入します。
今回の場合、以下ドキュメントに従い1.16.14 を導入しました。
https://docs.aws.amazon.com/ja_jp/snowball/latest/developer-guide/using-adapter.html
機器の受け取り
配送業者よりSnowball Edgeを受け取ります。
ダンボール等で梱包されている訳ではなく本体がそのまま輸送されてきます。
到着したSnowball Edgeさん
![]()
無骨なボディでかっこいいです!
いかにも頑丈で断熱しそうな素材で覆われているので雪のように冷たくはありません。
HDDの塊のようなものでもあるのですが、22.45kgと見た目やサイズの割には重たくはないですし、
パラレルグリップみたいなハンドルがついているので一般男性であれば運搬もそこまで苦ではないと思われます。
(サーバーワークス東京本社のリフレッシュルームに設置されているダンベルの方が重たいです)
おもむろに上のカバーを開けると電源ケーブル(日本で一般的なアースありのAタイプ)が入っています。
![]()
おもむろに前のカバーを開けると電源ボタンと固定されたタブレット(Fire)のモニターが現れます。
![]()
おもむろに後ろのカバーを開けるとRJ45(10G Base-T)、SFP+(25G)、QSFP+(40G)、USB3.0*2(非データ移行用)といった相当たるインターフェース群が現れます。
![]()
おもむろに電源ケーブルを差し込むと同時に電源がONとなり、
「ゔぼぉぉぉぉぉ」とやや低くて渋いサウンド(HP DLシリーズ比)を奏でながら起動してきます。
こんな音量でずっと動くのか・・・?と最初驚きましたが、
起動時の30-40sec程度ファンが100%で周り続けるだけで、その後は静かに落ち着きました。
フロントパネルを見るとFireの起動画面 -> Snowball Edgeにようこそ的な動画 -> トップ画面に遷移します。
トップ画面のメニュータブは「EDGE , CONNECTION , HELP」の3つとシンプルな構成です。
![]()
早速、Snowball Edgeに利用するIPアドレスを付与します。
「CONNECTION」を選択すると利用するインタフェースの選択タブとネットワーク設定の入力フォームおよびソフトウェアキーボードが現れるので設定します。スマートフォンをいじっている感覚で設定出来るので簡単、便利ですね。
![]()
IPアドレスの設定が完了すると上面のE-inkの情報にも反映されるようです。(初期状態だと 0.0.0.0 と表示されていました)
![]()
設定が完了したら、LANケーブル(今回はRJ45)を接続します。
このタイミングで同セグに接続したClient PCから Snowball Edgeに付与したIPアドレス宛にPingでの疎通確認を実施しておくと良いでしょう。
Snowball Edgeの Unlock
Snowball Edgeの利用を開始するためには、まずはUnlock作業を実施する必要があります。
Unlockに必要な情報として以下2点が必要となり、両方ともジョブが有効かつSnowball Edge本体が利用者の元にあるステータスの間のみジョブダッシュボードの認証情報から取得が可能です。
(1)マニフェストファイル (XXXはSnowball EdgeのデバイスID)
XXXXXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX_manifest-1.bin
ダウンロードして Snowball Edge Client が参照出来る場所に保存してください。
(2)クライアント解除コード (YYYはランダムな英数字)
YYYYY-YYYYY-YYYYY-YYYYY-YYYYY
![]()
準備ができたらSnowball Edge Clint導入済みのClient PCから Unlockコマンドを実行します。
マニフェストファイルをデスクトップ(C:\Users\LocalAdmin\Desktop\)に置いた場合は以下のようなコマンドになります。
C:\Users\LocalAdmin>snowballEdge unlock-device --endpoint https://192.168.0.10 --manifest-file C:\Users\LocalAdmin\Desktop\XXXXXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX_manifest-1.bin --unlock-code YYYYY-YYYYY-YYYYY-YYYYY-YYYYY
Your Snowball Edge device is unlocking. You may determine the unlock state of your device using the describe-device command. Your Snowball Edge device will be available for use when it is in the UNLOCKED state.
Unlockが完了すると フロントパネルの Amazon S3がUnlockingと表示され、しばらくすると Ready となり消費容量のインジケータが表示されます。
![]()
今回の場合、いきなり4.5TB消費しており、しかも容量が徐々に増えていくので、お客様と二人で「えっ」ってなったのですがこれで正常なようです。
起動後1時間程度で、初期消費容量が5TBぴったりで落ち着きました。(何が入っていてどんな処理がされていたのか少し気になります…)
とりあえず、この初期消費容量の値を基準にてデータ移行の進捗を把握する必要があるので数値を控えておくと良いと思います。
ここで「何故にServices に Amazon S3?」と思った方がいるかもしれませんが、Snowball Edgeでは仮想でAWSのS3のサービスのようなものが動作しており、利用者視点だとSnowball Edge内にまるでデータ移行先のS3のbucketが存在しているかのように見えます。なのでジョブ作成時に指定した S3 bucketのURIに対して後にAWS CLIでコマンドを発行する事となります。
初期の状態だとUnlock後に、Snowball Edgeコマンドを打つたび、いちいちマニフェストファイル等の指定が求められて大変なのでデータ移行期間中は、snowballEdge configure コマンドにて対話式にconfigファイルを作成しておくと便利です。
C:\Users\LocalAdmin>snowballEdge configure
Configuration will stored at C:\Users\LocalAdmin\.aws\snowball\config\snowball-edge.config
Snowball Edge Manifest Path: C:\Users\LocalAdmin\Desktop\XXXXXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX_manifest-1.bin
Unlock Code: YYYYY-YYYYY-YYYYY-YYYYY-YYYYY
Default Endpoint: https://192.168.0.10
C:\Users\LocalAdmin>
これで、Snowball Edgeコマンドが不自由なく利用出来るようになりました。
例えば、デバイスステータスを表示するコマンドを叩くと以下のような結果が返ってきます。
(マークした L35,36の値を使えばフロントパネルのインジケータを見ずに進捗を把握が出来そうですね)
C:\Users\LocalAdmin>snowballEdge describe-device
{
"DeviceId" : "XXXXXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX",
"UnlockStatus" : {
"State" : "UNLOCKED"
},
"ActiveNetworkInterface" : {
"IpAddress" : "192.168.0.10"
},
"PhysicalNetworkInterfaces" : [ {
"PhysicalNetworkInterfaceId" : "s.ni-XXXXXXXXXXXXXXXXX",
"PhysicalConnectorType" : "RJ45",
"IpAddressAssignment" : "STATIC",
"IpAddress" : "192.168.0.10",
"Netmask" : "255.255.255.0",
"MacAddress" : "XX:XX:XX:XX:XX:XX"
}, {
"PhysicalNetworkInterfaceId" : "s.ni-XXXXXXXXXXXXXXXXX",
"PhysicalConnectorType" : "QSFP",
"IpAddressAssignment" : "STATIC",
"IpAddress" : "0.0.0.0",
"Netmask" : "0.0.0.0",
"MacAddress" : "XX:XX:XX:XX:XX:XX"
}, {
"PhysicalNetworkInterfaceId" : "s.ni-XXXXXXXXXXXXXXXXX",
"PhysicalConnectorType" : "SFP_PLUS",
"IpAddressAssignment" : "STATIC",
"IpAddress" : "0.0.0.0",
"Netmask" : "0.0.0.0",
"MacAddress" : "XX:XX:XX:XX:XX:XX"
} ],
"DeviceCapacities" : [ {
"Name" : "HDD Storage",
"Unit" : "Byte",
"Total" : 99604758360227,
"Available" : 94227739443200
}, {
"Name" : "SSD Storage",
"Unit" : "Byte",
"Total" : 322122547200,
"Available" : 322122547200
}, {
"Name" : "vCPU",
"Unit" : "Number",
"Total" : 24,
"Available" : 24
}, {
"Name" : "Memory",
"Unit" : "Byte",
"Total" : 34359738368,
"Available" : 34359738368
}, {
"Name" : "GPU",
"Unit" : "Number",
"Total" : 0,
"Available" : 0
} ]
}
その他 Snowball Edgeコマンドについては以下URIを参照ください。
https://docs.aws.amazon.com/ja_jp/snowball/latest/developer-guide/using-client-commands.html
次に、AWS CLIを実行するためのconfigureの設定をします。
(少々紛らわしいですが、上の内容までは Snowball Edge Clientコマンドの話で AWS CLIとは別者です)
今回の構成では、Snowball Edge本体が AWSのS3サービスのような役目を果たすと上に書いた通り、
Snowball Edge本体へのアクセスキーおよびシークレットアクセスキーを利用してAWS CLIを実行します。
以下コマンドでSnowball Edgeへのアクセスキーを表示します。
C:\Users\LocalAdmin>snowballEdge list-access-keys
{
"AccessKeyIds" : [ "XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX" ]
}
C:\Users\LocalAdmin>
表示したアクセスキーを引数にシークレットアクセスキーを取得します。
C:\Users\LocalAdmin>snowballEdge get-secret-access-key --access-key-id XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
[snowballEdge]
aws_access_key_id = XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
aws_secret_access_key = YYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYY
C:\Users\LocalAdmin>
これで情報が揃ったのでaws configure等で設定をしておきます。
Default regionとoutput formatは特に指定せずで問題ありませんでした。
既存のcredentialsファイルがあれば、単純に上の内容のprofileとして追加すれば問題ありません。
(今回は新規で導入した端末なのでDefaultで Snowball Edgeのアクセスキーが使われるよう設定しました)
C:\Users\LocalAdmin>aws configure
AWS Access Key ID [None]: XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
AWS Secret Access Key [None]: YYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYY
Default region name [None]:
Default output format [None]:
C:\Users\LocalAdmin>
以下コマンドのように –endpointで Snowball EdgeのURIを指定し、
移行対象のS3 bucketに対しコマンドが正常に通れば成功です。(中身が空だとイマイチ感動が薄めですが…)
C:\Users\LocalAdmin>aws s3 ls s3://XXXXXXXXXXX --endpoint http://192.168.0.10:8080
C:\Users\LocalAdmin>
AWS CLIを利用した事のある方であればもうおわかりだと思いますが、ここまでくれば勝ったも同然といった感じで、あとは単純に ls ではなく cp やら syncで組む事で実際のデータ移行のコマンドになります。
本番の移行実行前のタイミングで想定どおりの速度が出るかを容量の少ないディレクトリで速度計測目的のテストをすると良いでしょう。
今回は、ファイルサイズ傾向が平均的で少なすぎず多すぎずの10GB程度のディレクトリをお客様が見つけてくださったので、そこで想定パフォーマンスが出るか否かを /Speedtest という仮の場所で処理を実行し何度かテストしました。
後にテスト用で利用した場所(/Speedtest)をrmする必要があるのが手間ですが、ファイルサイズ傾向が異なるディレクトリ等で実機のフォーマンス傾向を細かく分析する必要がある時などは事前にターゲットを調査のうえ実施する他ないと思われます。
仮の場所でパフォーマンステストした際のコマンド例
aws s3 cp --recursive \\192.168.0.30\ArchiveData\[10GB程度のちょうどよいディレクトリ] s3://XXXXXXXXXXX/Speedtest/ --endpoint http://192.168.0.10:8080
本番データ移行で利用したコマンド例 (異なるコマンドプロンプトから5パラで実行)
※細かい時間計測をしたい場合、末尾に && echo %date% %time% とかしておくと良いと思います。(Linuxであれば ;date)
aws s3 cp --recursive \\192.168.0.30\ArchiveData s3://XXXXXXXXXXX/ArchiveData/ --endpoint http://192.168.0.10:8080
aws s3 cp --recursive \\192.168.0.30\ArchiveData2 s3://XXXXXXXXXXX/ArchiveData2/ --endpoint http://192.168.0.10:8080
aws s3 cp --recursive \\192.168.0.31\ArchiveData3 s3://XXXXXXXXXXX/ArchiveData3/ --endpoint http://192.168.0.10:8080
aws s3 cp --recursive \\192.168.0.31\ArchiveData4 s3://XXXXXXXXXXX/ArchiveData4/ --endpoint http://192.168.0.10:8080
aws s3 cp --recursive \\192.168.0.31\ArchiveData5 s3://XXXXXXXXXXX/ArchiveData5/ --endpoint http://192.168.0.10:8080
今回のケースでは移行元ボリューム単位で、5パラで実行しましたが、2パラの段階でClientのCPU利用率およびネットワーク使用率があっけなく100%に張り付いてしまいました。移行パフォーマンスも 大体110MB/s=880Mbps程度と1Gbps回線を使い切って頭打ちという状態でした。(まぁ当環境でのベストは尽くせたといった感じです)
結果として当環境での約30TBのコピー処理は 4.20days (100.8h)で完了しました。
(修正予想よりやや遅かったのは USB2.0のHDD分がバスのボトルネックで足を引っ張ったと推測しています)
このようにSnowball Edge ClientではCPU利用率とネットワーク使用率が100%で張り付いた過酷な負荷状態がデータ移行完了までの数日間ずっと続いたりしますのできちんと冷却の効いたマシンにやさしい環境を必ず用意してあげてください。
データ移行後の整合性確認
次にデータ移行が正常に完了したかを確認します。
実は aws s3 cp コマンドもHash値の比較がされ、一致している場合のみ格納されるようかなり信頼性の高いコマンドとなりますが、何らかの原因で失敗したファイルの情報を差分として残せるので cp の後には sync コマンドを実施すると良いでしょう。
(Snowballではvalidateコマンドの実施が推奨されていますが、Snowaball Edgeでは該当しません)
単純に上の cp コマンドを sync に置き換えて実行するだけです。
aws s3 sync \\192.168.0.30\ArchiveData s3://XXXXXXXXXXX/ArchiveData/ --endpoint http://192.168.0.10:8080
今回は、32件インポート失敗している差分を検知しました。
(ディレクトリが失敗すると配下のファイルがすべて失敗するので実際に問題のあった箇所の件数でいえばもっと少ないですが)
差分検知時の出力例 (移行元には存在するが、Snowball Edge側にファイルが存在していない場合)
| warning: Skipping file \\192.168.0.30\Archivedata\hoge\piyo\fuga.txt File does not exist. |
詳細な原因までは特定できていないのですが、ディレクトリにS3で推奨されない文字列が混在していたり移行元環境側の問題(一時的に破損ファイルのように参照された)と思われる内容もありました。
検知した内容についてはお客様のほうで、別途データ移行完了後に手動アップロードでの対応を実施頂きました。今回は手作業でなんとかなる程度でしたが、環境によってはかなりネガティブな作業となってしまう場合があるのでリスクとして認識しておいたほうが良いでしょう。
Snowball Edgeの返送
データ移行処理がすべて完了したら返送の対応に進みます。
Snowball Edge に対して何も処理が実行されていない事を確認してから、おもむろにフロントの電源ボタンを押下します。(長押しではなく1sec程度押して離す感じで大丈夫です)
すると20-30secぐらいで電源が切れます。
シャットダウン中ですとかその手の前触れのような事はなく突然電源が落ちる感じなので電源ボタンを押したらしばらくは何も触らずに見守りましょう。
その後は集荷の手順に従い、Snowball Edgeの側面に返送用配送ラベルを貼り宅配業者へ集荷の手配をし引き渡すだけです。(今回はお客様に対応頂きました)
仕分け施設へ輸送されているSnowball Edgeのステータス
![]()
S3へのインポート
あとは AWS側が S3へのインポート対応の完了を待ちます。
AWSへ輸送された Snowball Edgeは順次インポートが開始されます。
ジョブダッシュボードではこのようにインポートの処理の進捗まで可視化されているので安心ですね。
![]()
進捗から計算したところ今回のインポートの場合は、143.25 MB/S = 1,146Mbps程度のパフォーマンスが出ていました。
今回はインポート処理開始から 2.50days (60h10min) で完了しました。
インポート完了後の対応
インポートが完了後するとマネージドコンソールのジョブダッシュボードより「ジョブレポート」、「成功ログ」、「失敗ログ」の取得が可能となります。
![]()
ジョブレポートは、PDF形式のファイルでインポート処理詳細と対応に関する時系列の情報が書かれています。(今回は取得し、お客様へ送付しました。)
ジョブレポートのサンプル
![]()
成功ログのダウンロードを押下すると
481MBで2,988,684行の以下CSVファイルがダウンロード出来ました。(ちょっとビビりました)
job-XXXXXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX-success-log-decoded.csv
中身は以下3カラムでインポートしたオブジェクト分の内容がずらずらと出力されているものでした。
% head -n 4 job-XXXXXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX-success-log-decoded.csv
"S3 Transfer Results Begin"
"Bucket Name","S3 Key","Size"
"XXXXXXXXX","Archivedata/hoge/piyo/fuga.txt","6555"
"XXXXXXXXX","Archivedata/foo/bar/baz.txt","81920"
%
失敗ログのダウンロードを押下すると
今回インポート失敗はなかったので Zero Byteの以下CSVファイルをダウンロード出来ました。
job-XXXXXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX-failure-log-decoded.csv
その後、お客様の方で何箇所でピックアップでS3での動作確認を実施頂き特に問題はなかったので、今回のミッションは無事完了となりました。
まとめ
初めてSnowball Edge利用したのですが、簡単に安定したパフォーマンスでデータ移行が出来ました。AWSへのデータ移行でお悩みで、もし条件を満たすようであればSnowball Edgeの利用を検討してみてください。
Snowball Edgeを利用したデータ移行作業は「段取り八分」と言えます。
事前調査や事前準備は入念に行い、いざ現地で困るような事が極力無いようステークホルダー全員が意識し進める事が大切です。
Snowballは、AWSでは珍しい物理(L1)をユーザが取り扱うサービスです。故に信頼性の高い物理環境をユーザ側で用意することが必要不可欠です。
この手の作業環境は会社やら組織で「余っている物の寄せ集め」になりがちですが、以下のうちどれか一つが欠けるだけでもデータ移行は成功しないので十分に注意しましょう。
・Client PCの品質
・ケーブルの品質
・L2SWの品質
おわりに
いかがだったでしょうか?
サービスの特性上、AWSエンジニアでも普段から気軽に触れるものではないのでSnowball Edgeを利用した一つのデータ移行の作業例としてイメージが伝わったのであれば幸いです。
私自身もAWSに関わる仕事をしているとL3以上な世界が多いので、たまにはL1と戯れるというのも新鮮でどこか懐かしくもありとても面白かったです。
個人的にSnowball Edgeの機器本体も良く出来ていると思いましたが、何よりマネージドコンソールのジョブダッシュボードがユーザにとても親切かつわかりやすく洗練されている点に一番感動しました。
ただ、寄せ集めた機器の不慣れな現地環境で新しい事をする訳ですから現場では色々な事が起こり得ます。
今回も大きなトラブルこそないものの、小さなトラブルは色々とありました。
(L2SWの設定がアレだったり、ケーブルも怪しくてはりなおしたり、ClientのH/Wトラブルで想定パフォーマンスが出ずに休日に集まってその切り分けをしたり、まともな端末求め猛暑のなか飯田橋までダッシュしたり…etc)
今回のデータ移行ミッションがうまく完了できたのは素晴らしいAWSサービスの存在はもちろんですが、何よりお客様が強いオーナーシップで指揮/判断系統で引っ張ってくれた事、
お客様とサーバーワークスそれぞれで役割をきちんと果たし、同じ方向を向いて二人三脚で対応出来た事に他ならないと感じています。
ps.昨今は「誤家庭用」ではなく、ギリギリ「ご家庭用」といえるようなメタルの10GbEを搭載した安価なL2SWも市場には出始めています。
お客様も次はもっと良い機器揃えて1GbEの壁を超えたいね!と意気込んでおられましたしネクストステージも楽しみです。

 今回と前回の更新を踏まえ、各AZの特徴を再度まとめてみましょう。
今回と前回の更新を踏まえ、各AZの特徴を再度まとめてみましょう。






























































 DSMにログインします。
DSMにログインします。 別ウインドウでウィザードが表示されます。
別ウインドウでウィザードが表示されます。 アカウントのセットアップでは、特に何もせず「次へ」を選択します。
アカウントのセットアップでは、特に何もせず「次へ」を選択します。 ログインしていたAWSアカウントにてCloudFormationが起動します。
ログインしていたAWSアカウントにてCloudFormationが起動します。
 特に何も変更せず「次へ」を選択します。
特に何も変更せず「次へ」を選択します。 IAMリソースが作成されることを承認するにチェックを入れ、「スタックの作成」を選択します。
IAMリソースが作成されることを承認するにチェックを入れ、「スタックの作成」を選択します。 スタックのステータスが「CREATE_COMPLETE」になるまで暫く待ちます。
スタックのステータスが「CREATE_COMPLETE」になるまで暫く待ちます。 DSMの「コンピュータ」を確認すると、該当のAWSアカウントに構築されたEC2の一覧が表示されます。
DSMの「コンピュータ」を確認すると、該当のAWSアカウントに構築されたEC2の一覧が表示されます。
 別ウィンドウが表示されます。
別ウィンドウが表示されます。 下にスクロールすると、実行するスクリプトが確認できます。
下にスクロールすると、実行するスクリプトが確認できます。

 DSMにログインしてコンピュータを確認すると、対象インスタンスのステータスが「管理対象(オンライン)」になりました。
DSMにログインしてコンピュータを確認すると、対象インスタンスのステータスが「管理対象(オンライン)」になりました。 対象インスタンスの詳細画面を確認すると、有効にしている機能毎にステータスを確認することができます。
対象インスタンスの詳細画面を確認すると、有効にしている機能毎にステータスを確認することができます。
 コマンドのパラメータには、DSMからダウンロードしたスクリプトの内容を貼り付けます。
コマンドのパラメータには、DSMからダウンロードしたスクリプトの内容を貼り付けます。 ターゲットは「Choose instances manually」を選択し、DSAのインストールする対象となるEC2インスタンスを選択します。
ターゲットは「Choose instances manually」を選択し、DSAのインストールする対象となるEC2インスタンスを選択します。 コマンドが失敗した場合などの内容を確認したい場合は「CloudWatch出力」チェックを入れます。
コマンドが失敗した場合などの内容を確認したい場合は「CloudWatch出力」チェックを入れます。 コマンドが実行され、ステータスが「進行中」から「成功」になるまで暫く待ちます。
コマンドが実行され、ステータスが「進行中」から「成功」になるまで暫く待ちます。 ステータスが「成功」になりました。
ステータスが「成功」になりました。 DSMにログインしてコンピュータを確認すると、対象インスタンスのステータスが「管理対象(オンライン)」になりました。
DSMにログインしてコンピュータを確認すると、対象インスタンスのステータスが「管理対象(オンライン)」になりました。 セッションマネージャの時と同様、対象インスタンスの詳細画面からもステータスが正常であることを確認できます。
セッションマネージャの時と同様、対象インスタンスの詳細画面からもステータスが正常であることを確認できます。







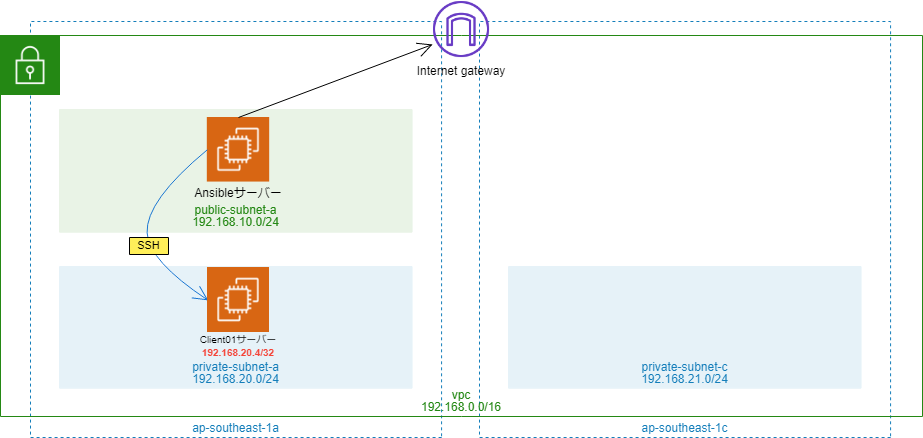
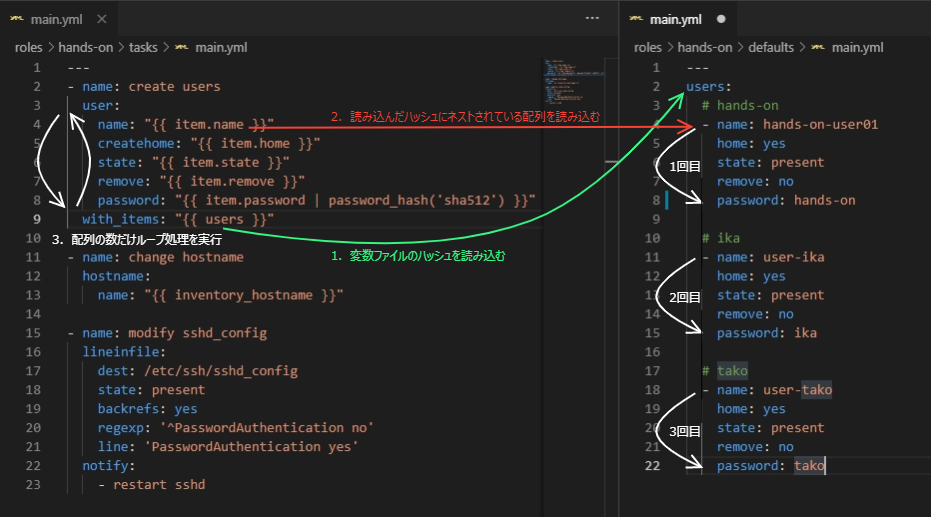
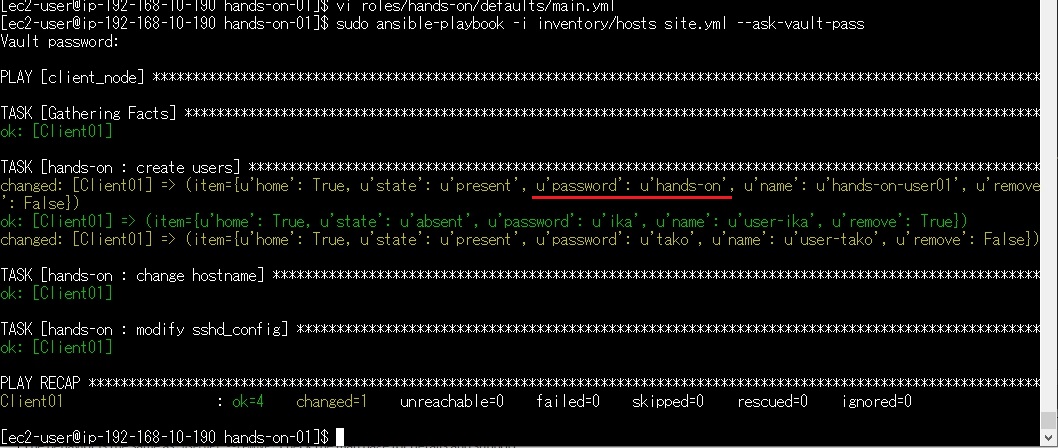
 わざわざ変数のパラメーターを書く必要がありませんので、とても楽ですね♪
わざわざ変数のパラメーターを書く必要がありませんので、とても楽ですね♪