こんにちは。SRE2課福島です。
家の掃除をするのがめんどくさく、先月くらいにブラーバジェットという
床拭きロボットを買ったのですが、今は、ブラーバジェットに付ける
クリーニングパッドを付けるのが、めんどくさくなっています。
さて今回は、ECSクラスタ(EC2)のインスタンスタイプを変更する際は、
注意が必要です、という内容のブログを書きたいと思います。
結論
結論を先に記載すると普通のEC2と同じように
停止 ⇒ インスタンスタイプの変更 ⇒ 起動する方法では、
上手くいかないということです。
ECSクラスタの起動モードについて
ECSクラスタ(EC2)の()は、起動モードを指しているのですが、
そもそも、起動モードについて、知らない方向けに簡単に説明したいと思います。
ECSクラスタの起動モードには、EC2とFargateが存在し、大きな違いは、以下の通りです。
| EC2 |
コンテナが稼働するEC2を管理する必要がある |
| Fargate |
コンテナが稼働するEC2を管理する必要がない |
起動モードがEC2の良い点は、自分たちで管理する必要はありますが、
SSHでログインが可能という点(Fargateの場合できない)と、ログインできるため、
トラブルシューティング時に詳細な調査ができるという点なのかなと思ってます。
ちなみにですが
ちなみにですが、コンテナが稼働するEC2は、
ECSエージェントを起動することで、ECSクラスタと連携しております。
ちなみにからのちなみにですが、ECSエージェントが導入されたAMIも存在します。
ちなみにからのちなみにからのちなみにですが、
ECSクラスタのことをコントロールプレーン、
コンテナが稼働するEC2をデータプレーンと呼びます。
Blackbelt(コントロールプレーン / データプレーン)
これ以降、コンテナが稼働するEC2をコンテナインスタンス、起動モードがEC2のことをEC2と記載いたします。
コンテナインスタンスのインスタンスタイプ変更手順について
話が脱線してしまいましたが、ここから本題です。
上記で記載した通り、EC2の場合、コンテナインスタンスを自分たちで管理する必要があるので、
インスタンスタイプの変更も、自分たちで行う必要があります。
インスタンスタイプの変更は、ECSクラスタにコンテナインスタンスを登録する方法によって、
手順が異なりますので、まずは、2種類ある登録方法について、説明します。
①ECSクラスタ作成時にコンテナインスタンスを作成する方法
②ECSクラスタ作成後に手動でコンテナインスタンスを登録する方法(AutoScaling有り)
①ECSクラスタ作成時にコンテナインスタンスを作成する方法
ECSクラスタ作成時にコンテナインスタンスを作成することが可能なのですが、
その場合、裏側でCloudFormationが実行されています。
以下の画像の通り、「空のクラスターの作成」にチェックを入れずに構築します。
![]()
②ECSクラスタ作成後に手動でコンテナインスタンスを登録する方法(AutoScaling有り)
ECSクラスタは、コンテナインスタンスを登録せずに
空のクラスタとして、作成することが可能です。
今度は、以下の画像の通り、「空のクラスターの作成」にチェックを入れて構築します。
![]()
その場合、手動でコンテナインスタンスをECSクラスタに登録する必要があります。
ECSエージェントの設定ファイル(/etc/ecs/ecs.config)に「ECS_CLUSTER=ECSクラス名」を
定義するだけです。
コンテナインスタンス作成時にユーザーデータを以下のイメージで設定する感じです。
※ECSエージェントが導入されているAMIを利用する前提です。
#!/bin/bash
echo ECS_CLUSTER=test-ecs-cluster >> /etc/ecs/ecs.config
この際、作成するコンテナインスタンスは、AutoScalingを組んでいる前提です。
①、②に応じたインスタンスタイプ変更手順
そして、それに応じたインスタンスタイプの変更手順は、以下の通りです。
①の場合、CloudFormationを更新し、インスタンスタイプを更新します。
②の場合、AutoScalingの設定を更新します。
詳細な手順は、以下を参照してください。
Amazon ECS でコンテナインスタンスタイプを変更する方法を教えてください。
②でAutoScalingの設定を組んでない場合の対応
上記の②は、AutoScalingを組んでいる前提で記載されておりますが、
もし、AutoScalingを組んでいない場合の対応についてです。
冒頭に記載しましたが、普通のEC2インスタンスのように
停止 ⇒ インスタンスタイプの変更 ⇒ 起動する方法では、
上手くいきません。(ECSエージェントが正常に起動しません。)
実際にやってみると・・・
t2.nanoからt2.microに変更しました。
ECSエージェントが起動していない…
# docker container ls
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
#
ログを確認してみると・・・
/var/log/ecs/ecs-agent.log
level=error time=2020-06-25T03:06:31Z msg=”Error re-registering: ClientException: Container instance type changes are not supported. Container instance ea56ffb2-2fc1-4d08-83bb-c4b90b3d02b2 was previously registered as t2.nano.\n\tstatus code: 400, request id: a0d431d8-03d6-43ca-bcf1-40483a6182ee” module=agent.go level=critical time=2020-06-25T03:06:31Z msg=”The current instance type does not match the registered instance type. Please revert the instance type change, or alternatively launch a new instance: ClientException: Container instance type changes are not supported. Container instance ea56ffb2-2fc1-4d08-83bb-c4b90b3d02b2 was previously registered as t2.nano.\n\tstatus code: 400, request id: a0d431d8-03d6-43ca-bcf1-40483a6182ee” module=agent.go
Google翻訳
level = error time = 2020-06-25T03:06:31Z msg = “エラー再登録:ClientException:コンテナインスタンスタイプの変更はサポートされていません。コンテナインスタンスea56ffb2-2fc1-4d08-83bb-c4b90b3d02b2は、以前にt2.nanoとして登録されていました 。\ n \ tステータスコード:400、リクエストID:a0d431d8-03d6-43ca-bcf1-40483a6182ee “module = agent.go level = critical time = 2020-06-25T03:06:31Z msg = “現在のインスタンスタイプは登録されたインスタンスタイプと一致しません。インスタンスタイプの変更を元に戻すか、代わりに新しいインスタンスを起動してください:ClientException:コンテナインスタンスタイプの変更は サポートされていません。コンテナインスタンスea56ffb2-2fc1-4d08-83bb-c4b90b3d02b2は、以前はt2.nanoとして登録されていました。\ n \ tステータスコード:400、リクエストID:a0d431d8-03d6-43ca-bcf1-40483a6182ee “module = agent.go
このようにコンテナインスタンスは、インスタンスタイプの変更にサポートしていない。
インスタンスタイプの変更を元に戻すか、代わりに新しいインスタンスを起動してください。
と出力さます。
なので、コンテナインスタンスのインスタンスタイプを変更する場合は、
新しいインスタンスを再構築する必要があります。
ただ・・・
ただ、エラーログの情報から、もしかして、内部情報を管理しているファイルがあるのでは?と考えました。
現在のインスタンスタイプは登録されたインスタンスタイプと一致しません。
そして、色々と探した結果、それっぽいものが、見つかりました。
# cat /var/lib/ecs/data/ecs_agent_data.json | jq
{
"Data": {
"Cluster": "test-ecs-cluster",
"ContainerInstanceArn": "arn:aws:ecs:ap-northeast-1:xxxxxxxx:container-instance/d81c95af-567c-4327-8a3b-deb21c944bbf",
"EC2InstanceID": "i-0d96884ecd588ffcb",
"TaskEngine": {
"Tasks": [],
"IdToContainer": {},
"IdToTask": {},
"ImageStates": null,
"ENIAttachments": null,
"IPToTask": {}
},
"availabilityZone": "ap-northeast-1a",
"latestSeqNumberTaskManifest": 3
},
"Version": 28
}
ということで、こうして、
mv /var/lib/ecs/data/ecs_agent_data.json /tmp
停止 ⇒ インスタンスタイプの変更 ⇒ 起動
すると・・・
# docker container ls
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
0d000d2b23aa amazon/amazon-ecs-agent:latest "/agent" 49 minutes ago Up 49 minutes (healthy) ecs-agent
#
ECSエージェントを無事に起動することができました。
「/var/lib/ecs/data/ecs_agent_data.json」も自動で作成されていました。
# cat /var/lib/ecs/data/ecs_agent_data.json | jq
{
"Data": {
"Cluster": "test-ecs-cluster",
"ContainerInstanceArn": "arn:aws:ecs:ap-northeast-1:xxxxxxxx:container-instance/ea56ffb2-2fc1-4d08-83bb-c4b90b3d02b2",
"EC2InstanceID": "i-0d96884ecd588ffcb",
"TaskEngine": {
"Tasks": [],
"IdToContainer": {},
"IdToTask": {},
"ImageStates": null,
"ENIAttachments": null,
"IPToTask": {}
},
"availabilityZone": "ap-northeast-1a",
"latestSeqNumberTaskManifest": 7
},
"Version": 28
}
変更前と変更後でdiffした結果、
ContainerInstanceArnとlatestSeqNumberTaskManifestの値が変わっていました。
インスタンスタイプを変更することでContainerInstanceArnが変わるのが
ecsエージェントが起動できなくなる原因なのかなと思いました。
と、こんな感じでやったけど
と、こんな感じで私が検証した際には、上記方法でコンテナインスタンスを
再構築することなく、インスタンスタイプを変更することができました。
ただし、エラーログに記載がある通り、インスタンスタイプを変更する際には、
コンテナインスタンスを再構築することを推奨します。
Blackbeltには、コンテナの中に入れるのは、ステートレスなアプリにすることで
コンテナのメリットを最大限活かせると記載があります。
Blackbelt(アプリのステートレス化)
この内容からもコンテナを使う上では、上記の手順を
実施しなくても(コンテナインスタンスに依存せず、再構築できる)
問題ない設計にすることが大切なのかなと思います。
おわりに
今までDockerやECSを使ったことがなかったのですが、
色々検証やブログを書いている内に少しDockerやECSと仲良くなれた気がします。
これから、もっと仲良くなれるようになりたいですね~
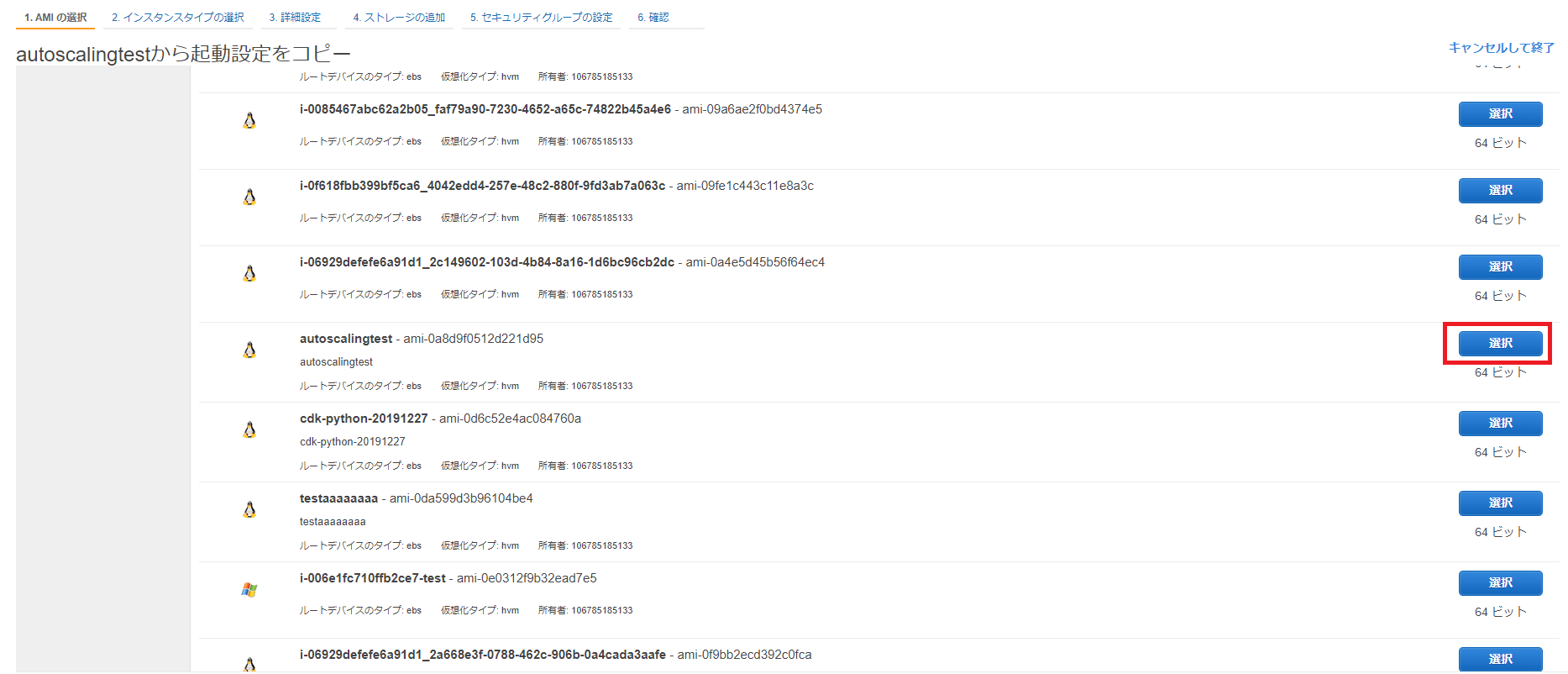
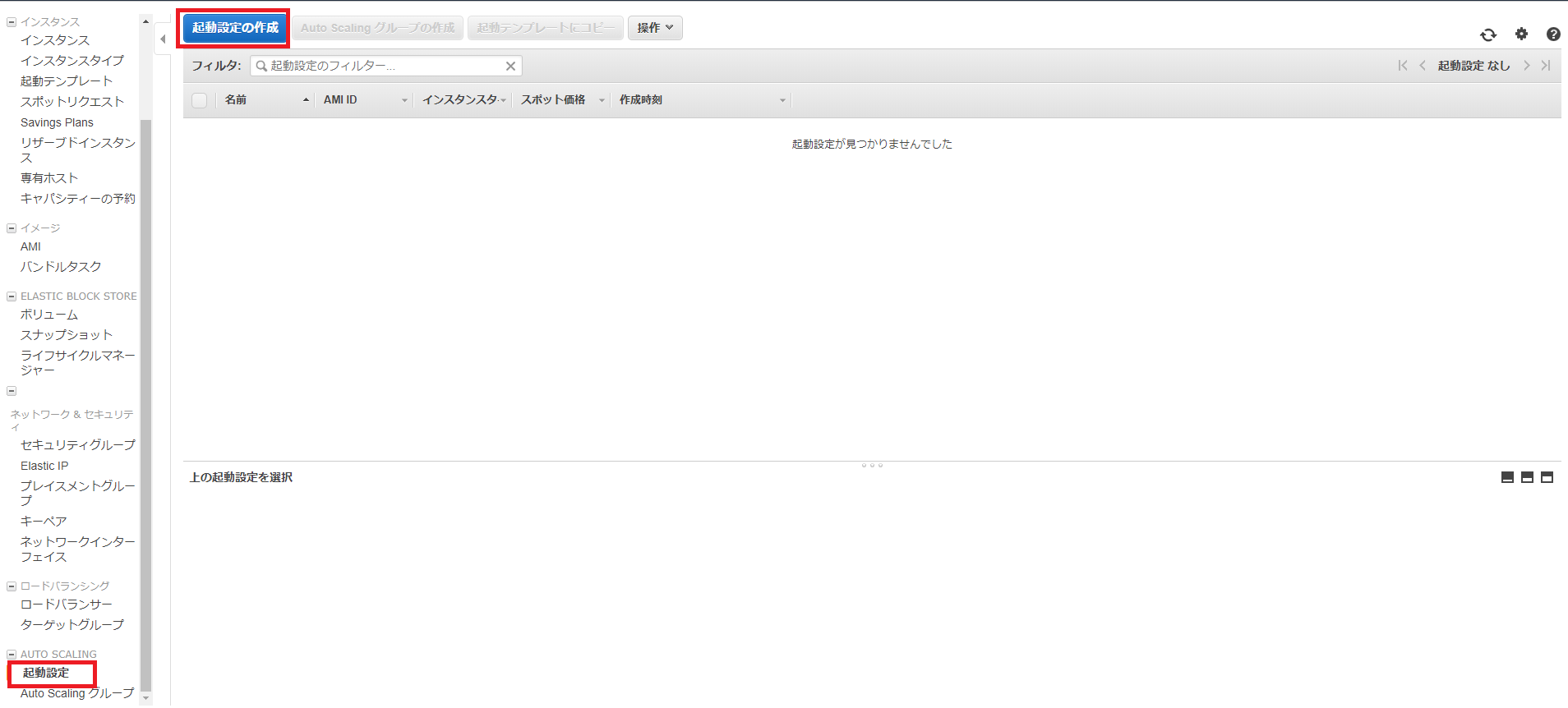 起動設定の作成でAMIの選択画面が表示されるので、Auto Scalingに使用するAMIを指定します(今回はAmazon Linux 2を選択しています)。
起動設定の作成でAMIの選択画面が表示されるので、Auto Scalingに使用するAMIを指定します(今回はAmazon Linux 2を選択しています)。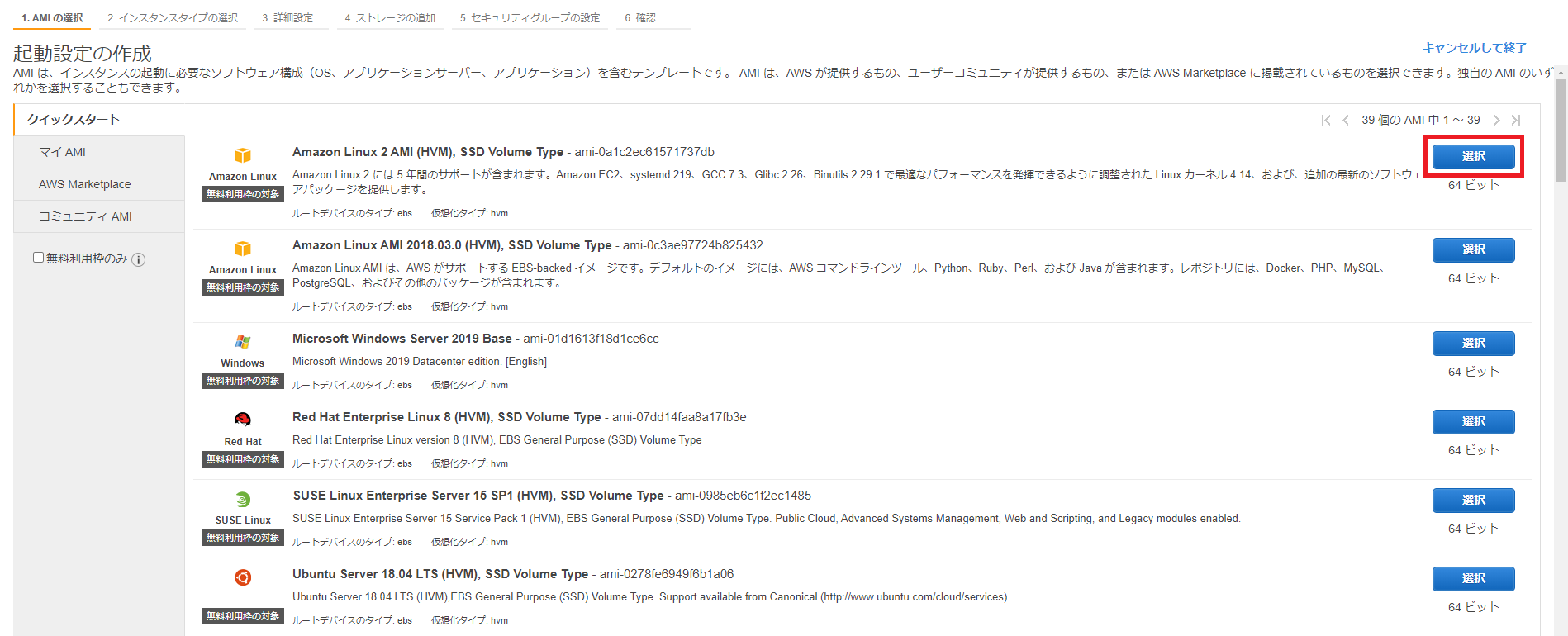
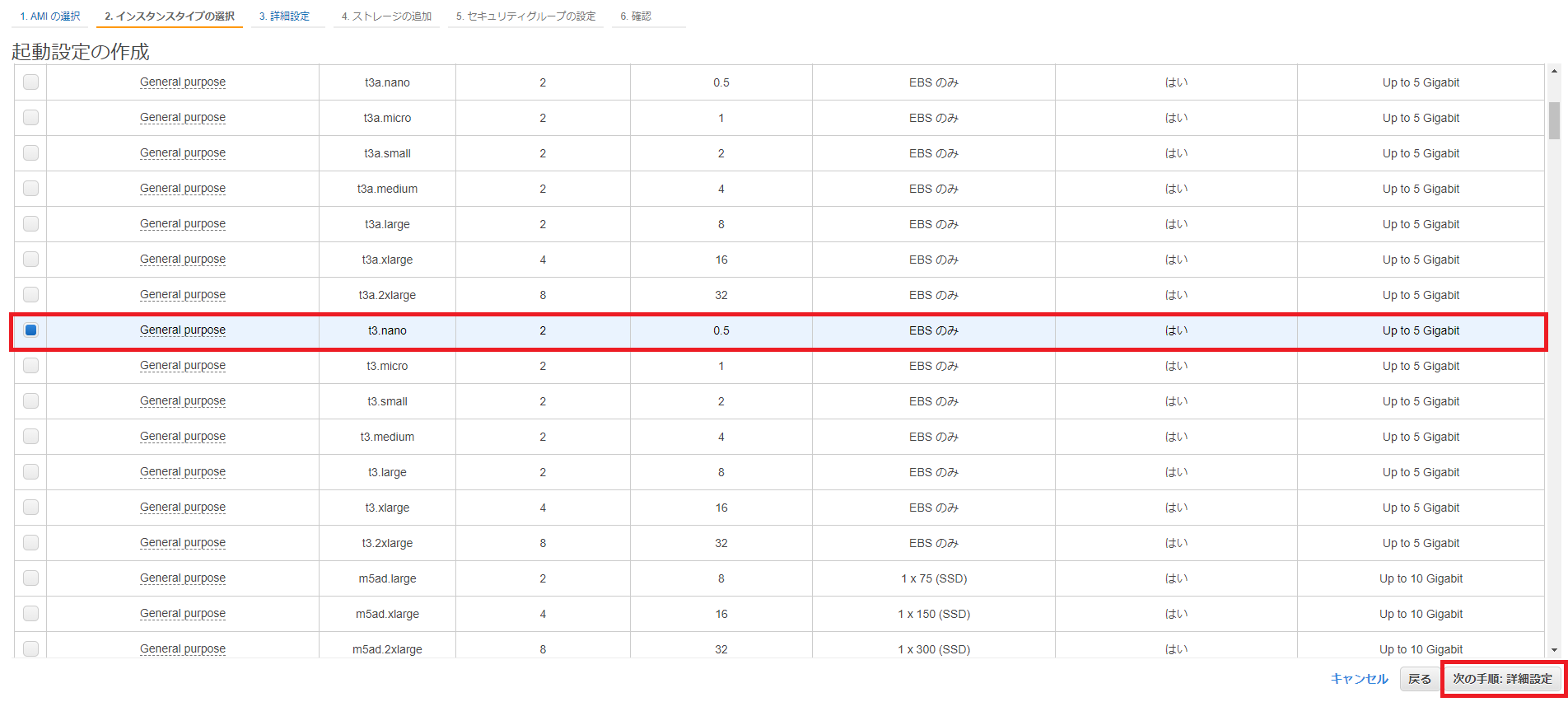

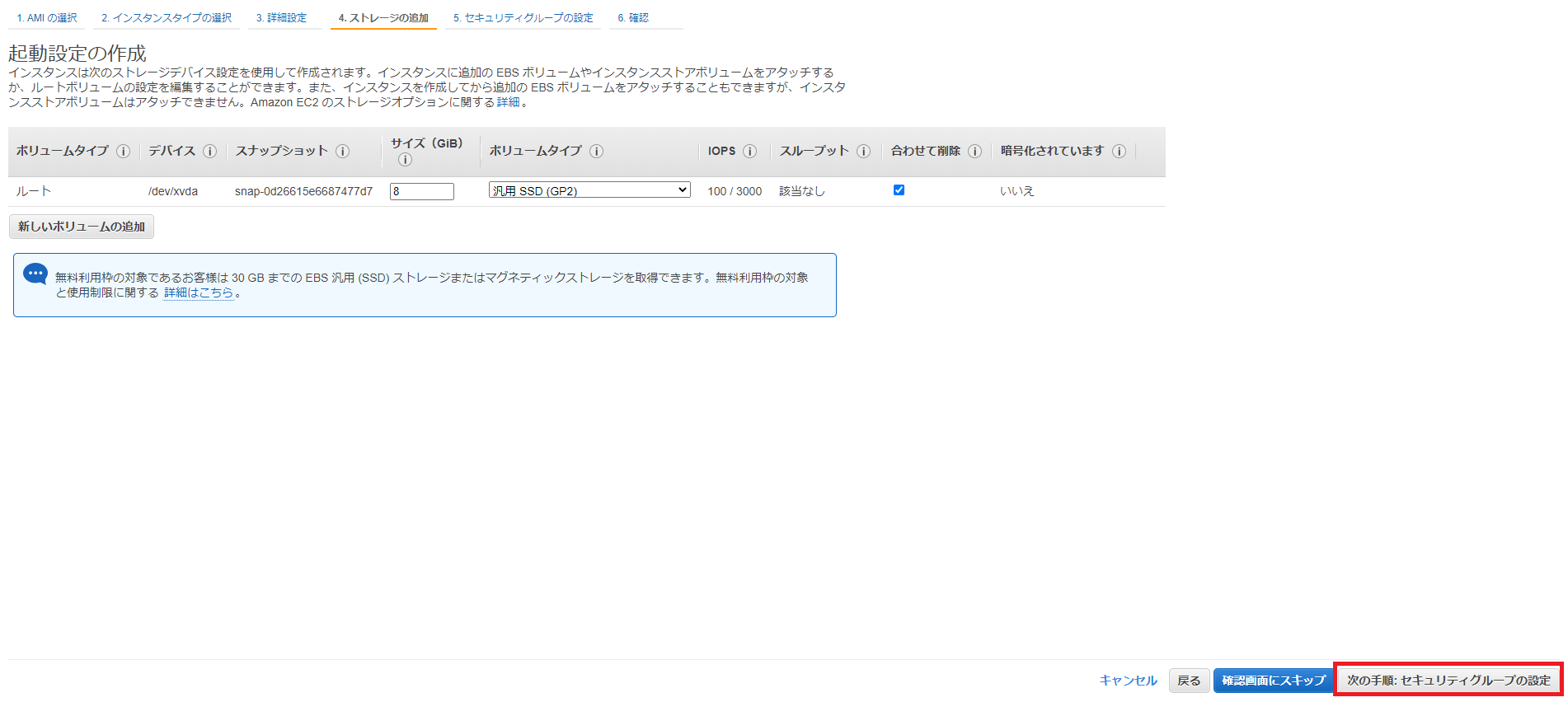
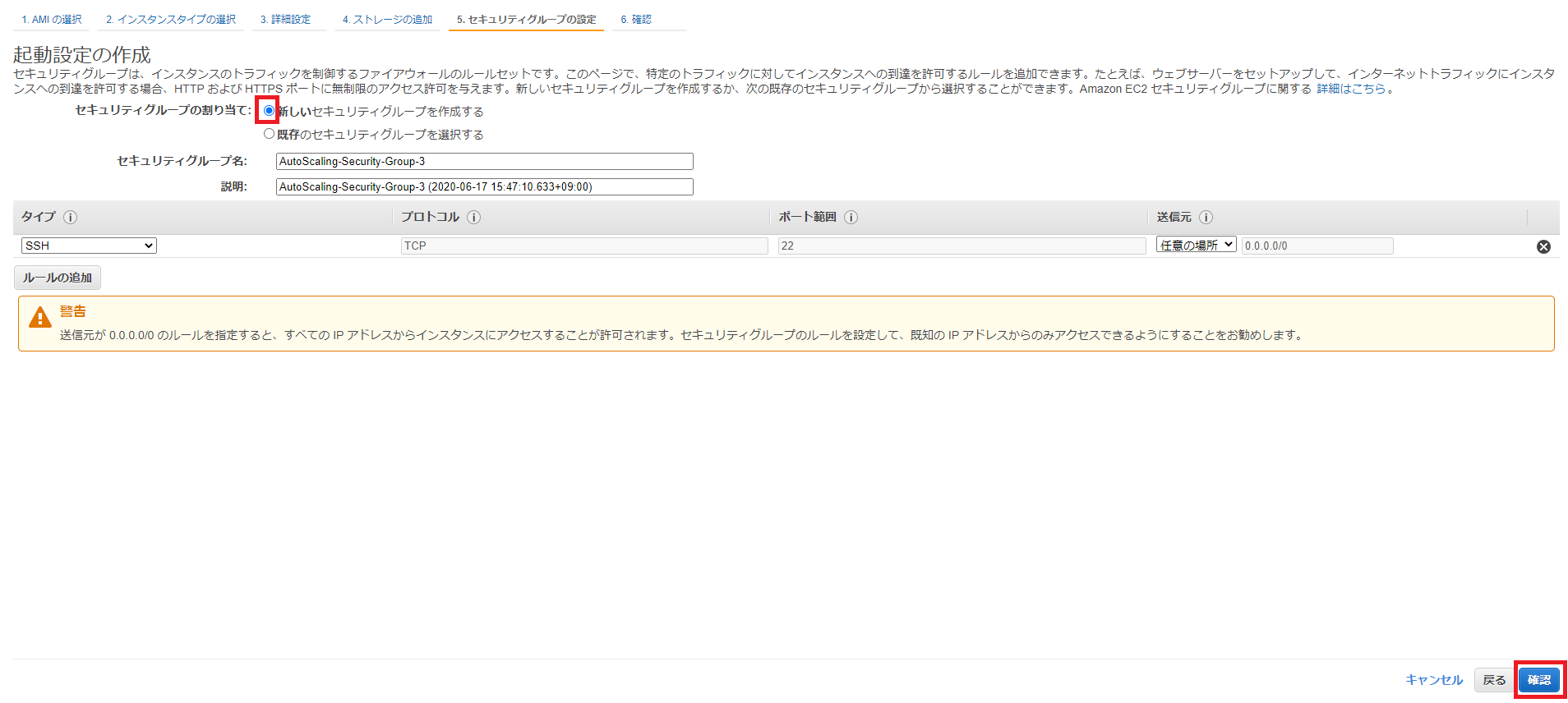 確認画面で設定内容を確認し、右下の[起動設定の作成]をクリックします。
確認画面で設定内容を確認し、右下の[起動設定の作成]をクリックします。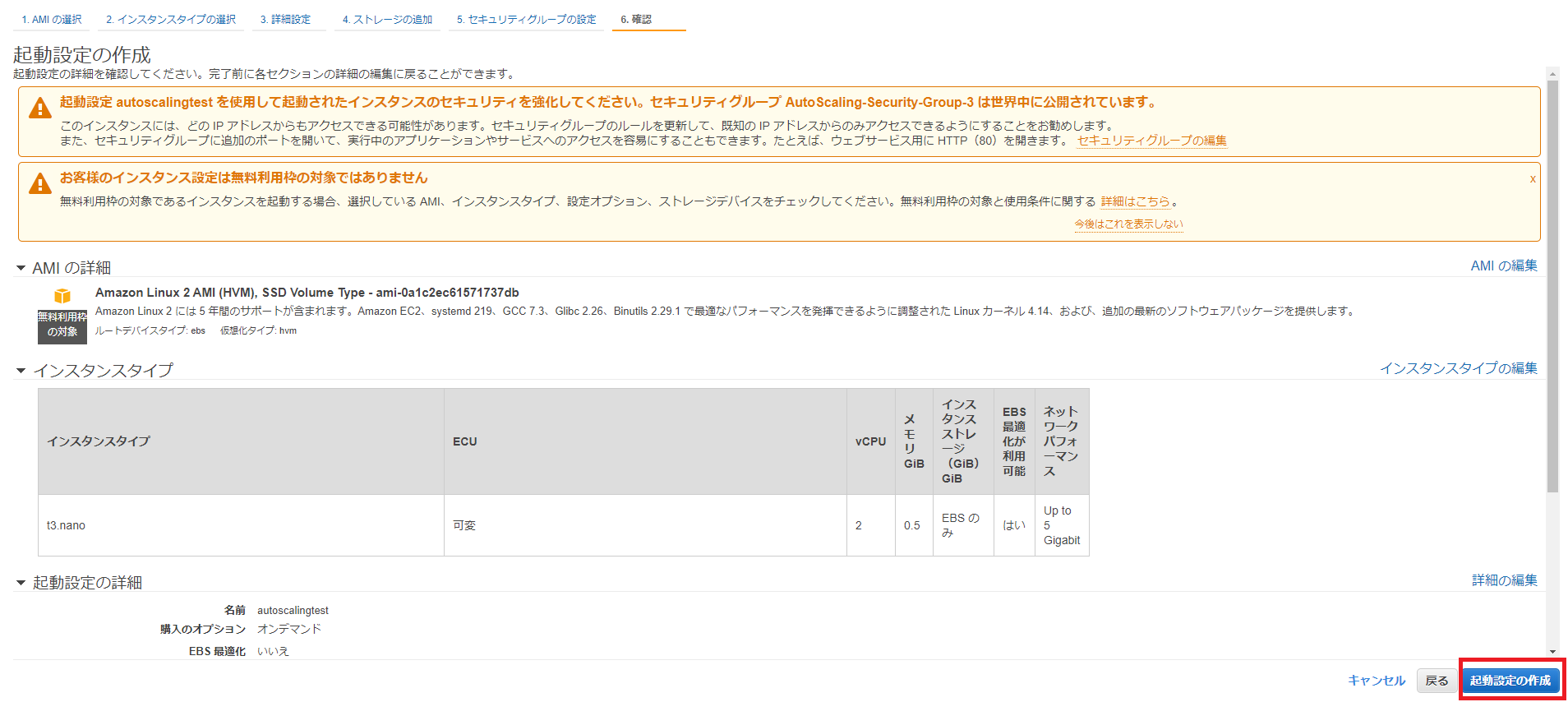
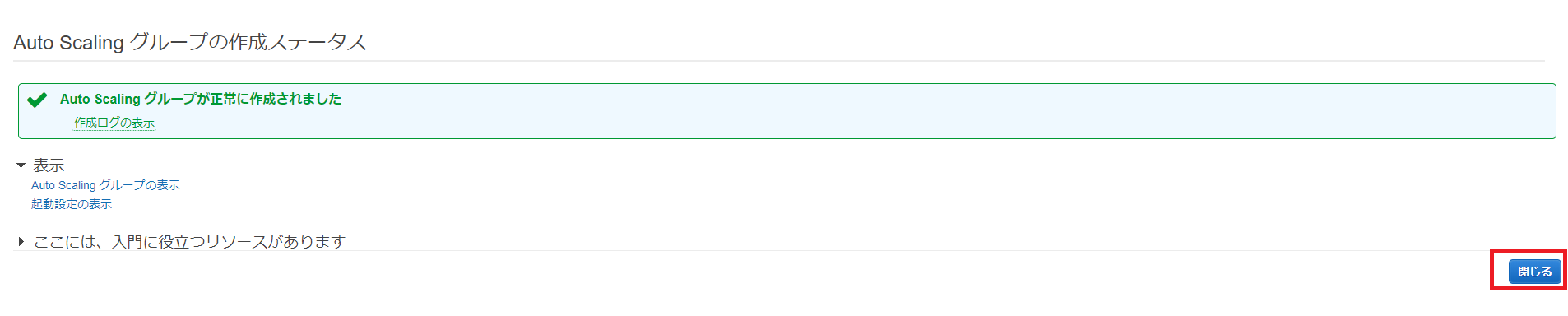
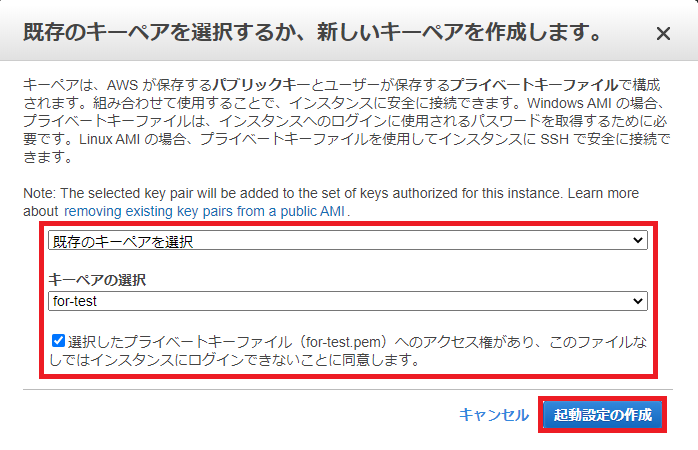 起動設定の作成ステータス画面が表示されるので、[この起動設定を使用してAuto Scalingグループを作成する]をクリックします。
起動設定の作成ステータス画面が表示されるので、[この起動設定を使用してAuto Scalingグループを作成する]をクリックします。 Auto Scalingグループの詳細設定画面が表示されるので、グループ名、グループサイズ、ネットワーク、サブネットを入力して、右下の[次の手順: スケーリングポリシーの設定]をクリックします。
Auto Scalingグループの詳細設定画面が表示されるので、グループ名、グループサイズ、ネットワーク、サブネットを入力して、右下の[次の手順: スケーリングポリシーの設定]をクリックします。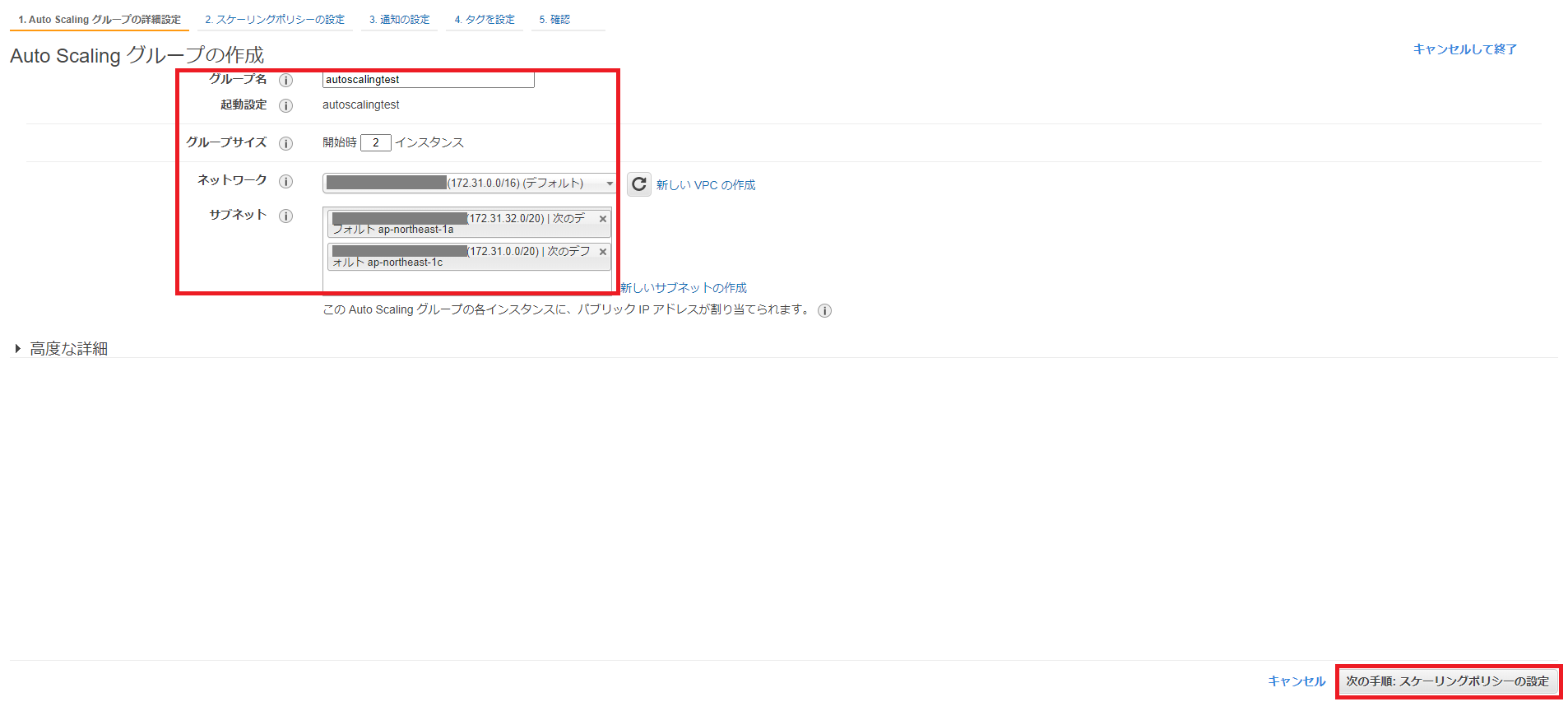
 確認画面が表示されたら、内容を確認して右下の[Auto Scalingグループの作成]をクリックします。
確認画面が表示されたら、内容を確認して右下の[Auto Scalingグループの作成]をクリックします。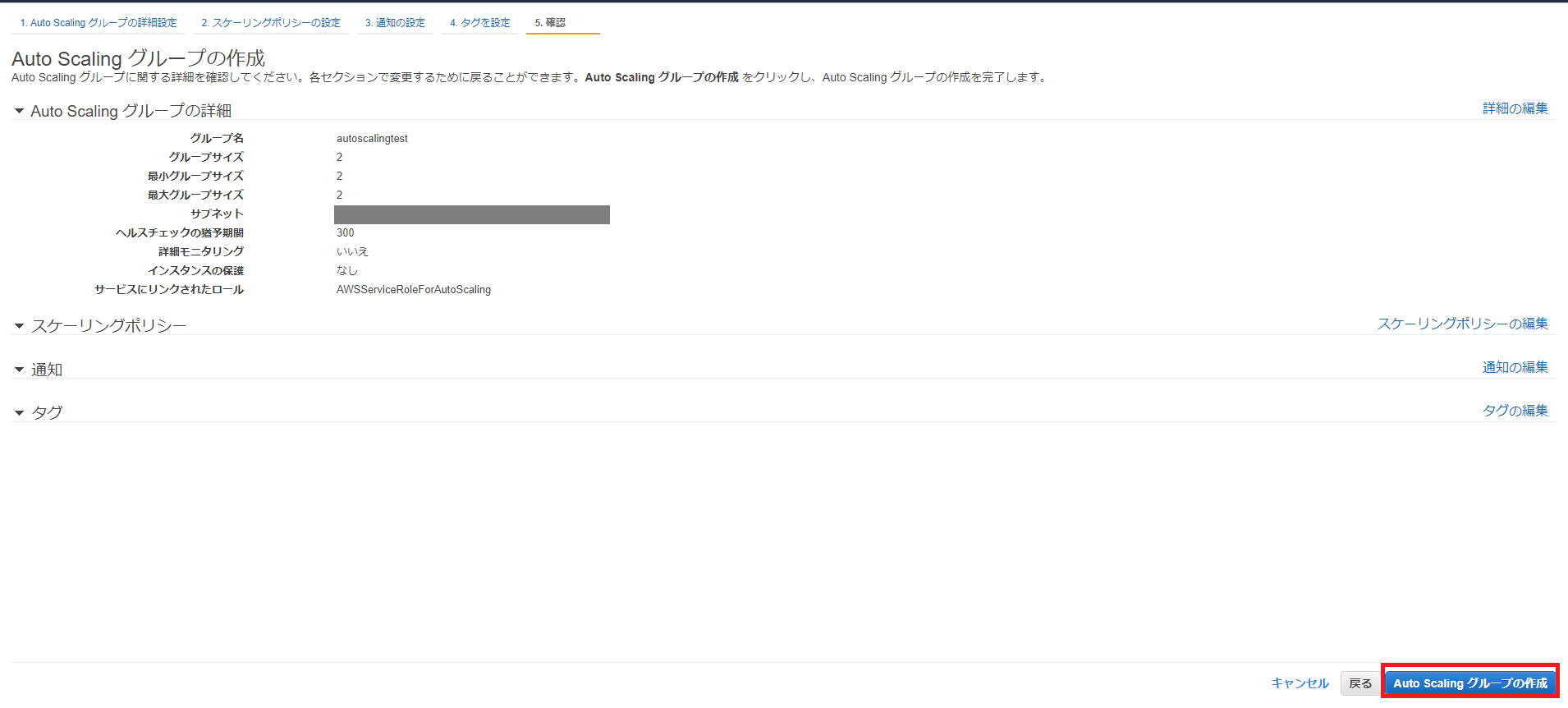


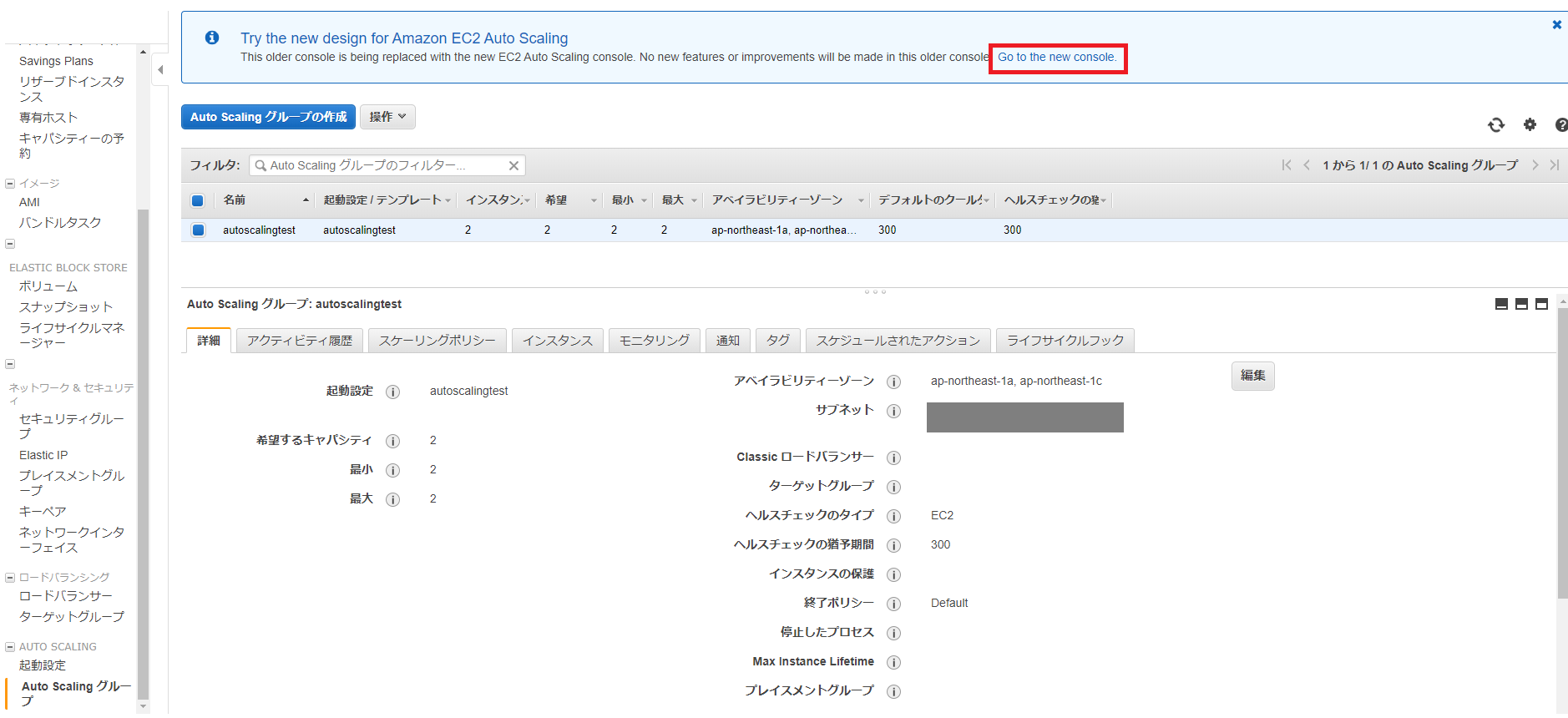
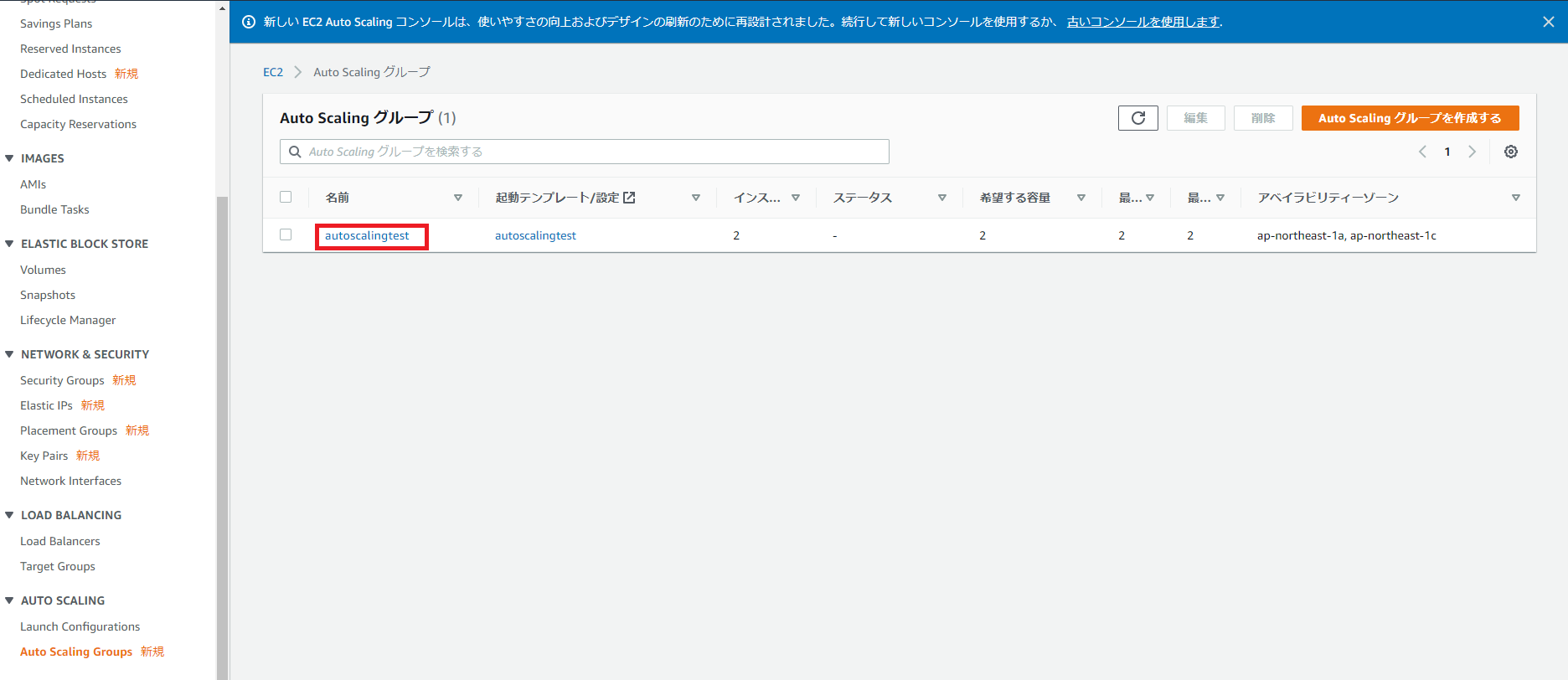
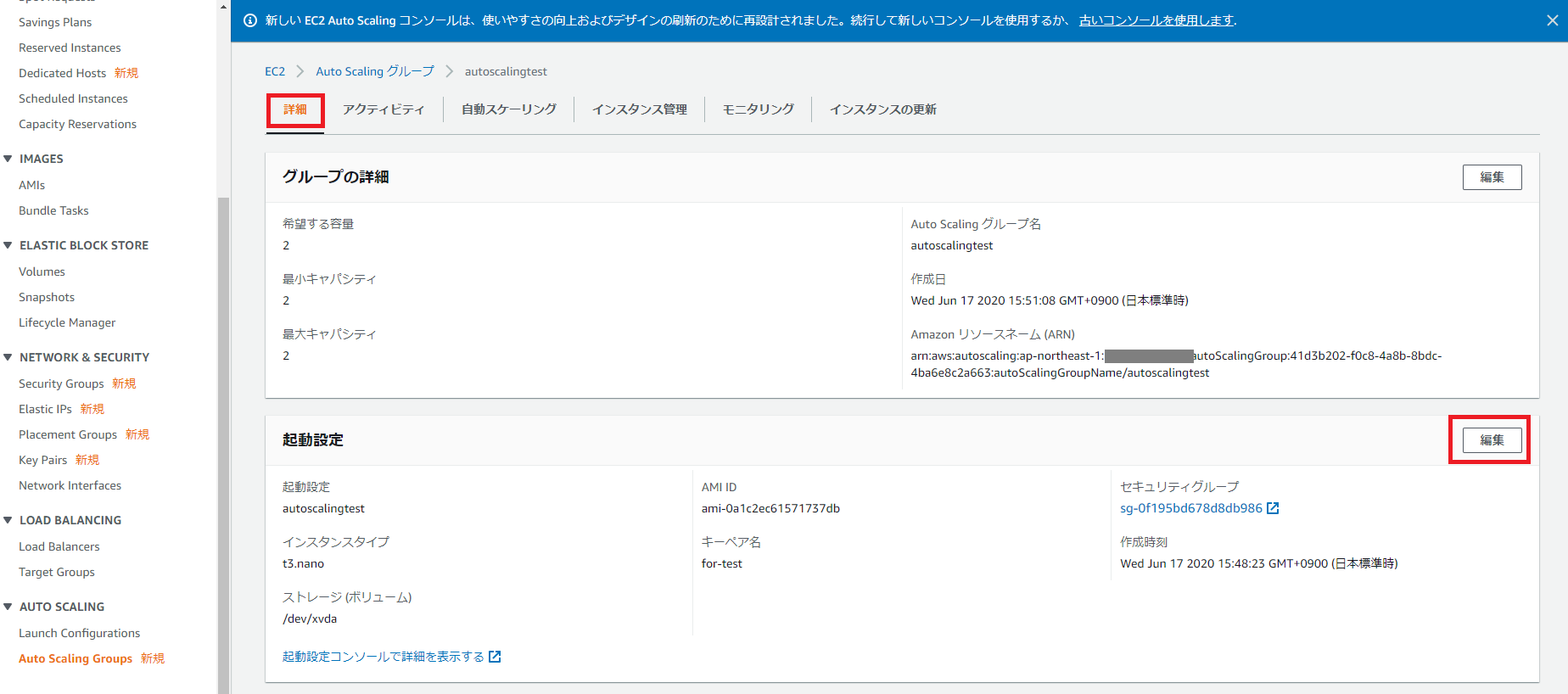
 起動設定が変更されました。
起動設定が変更されました。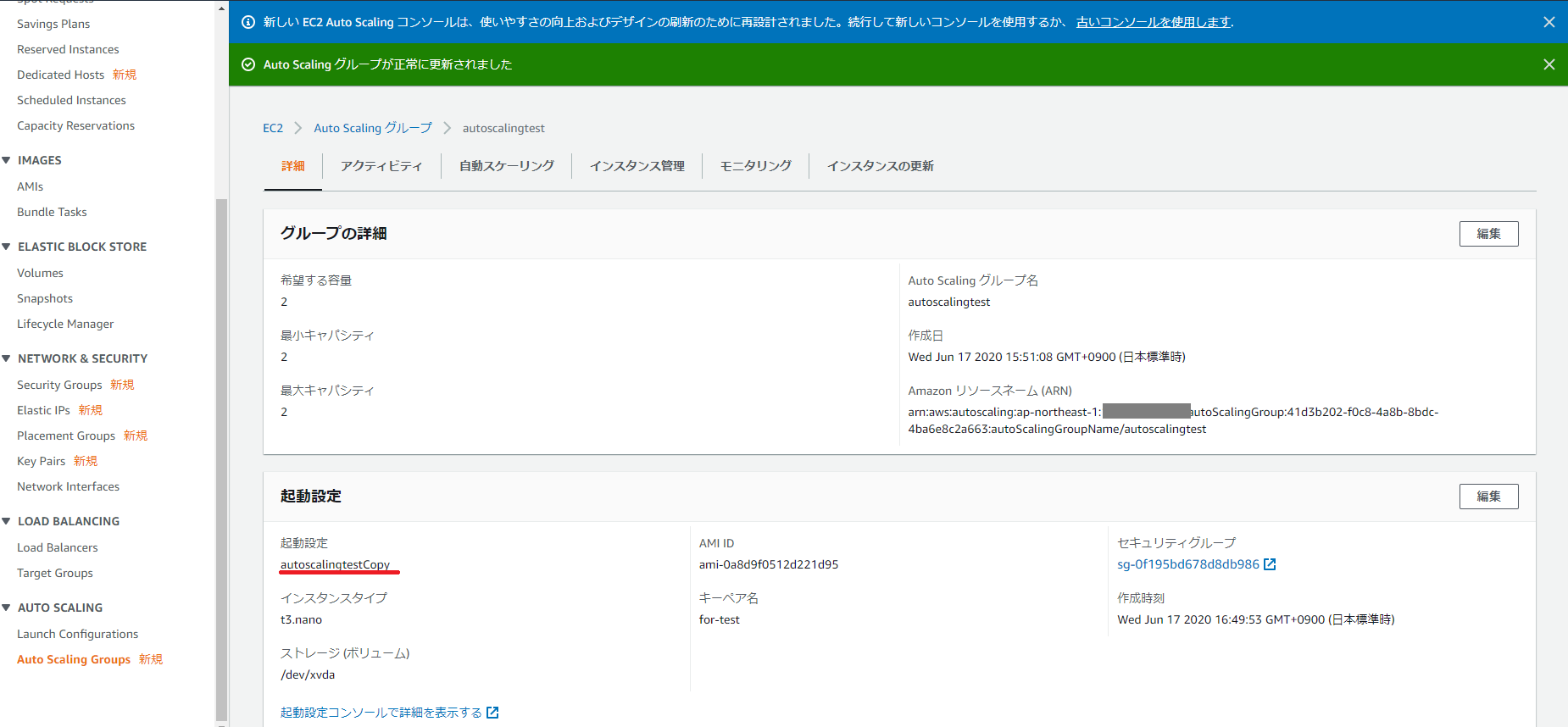
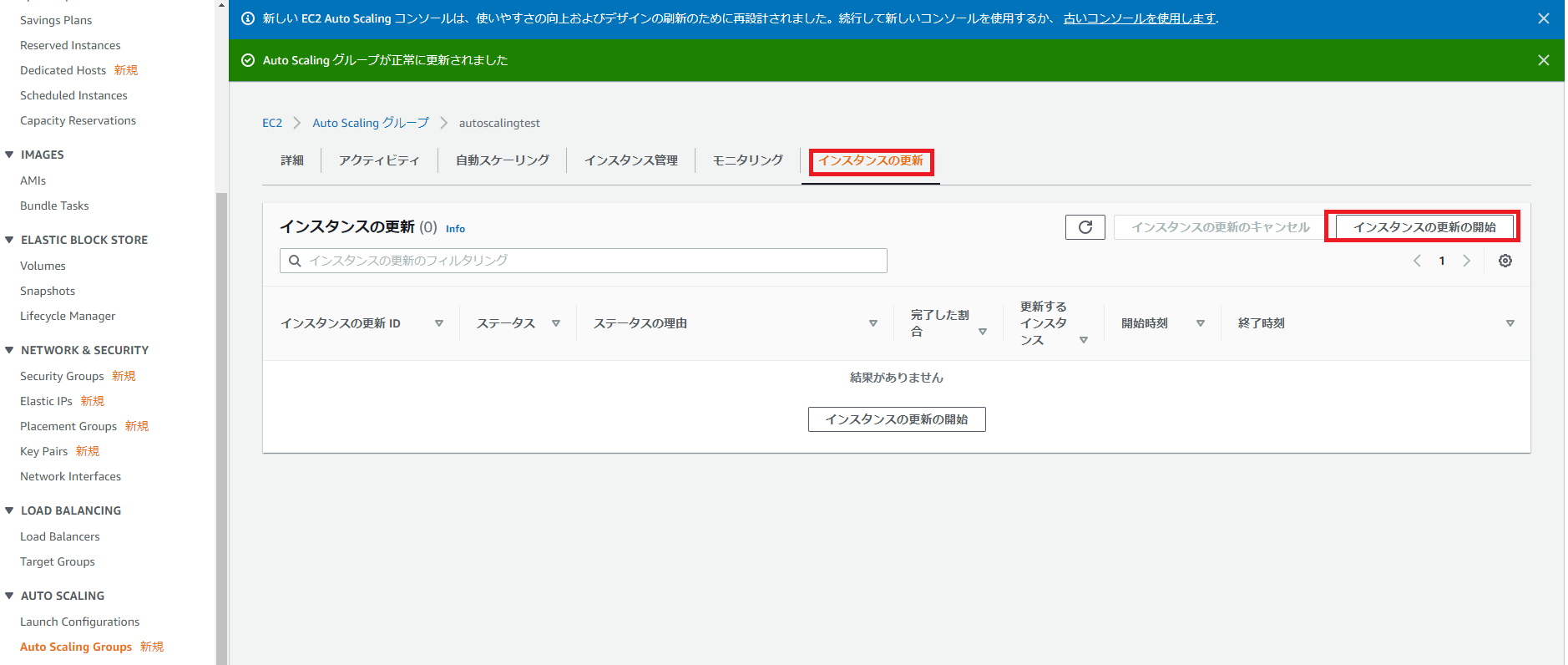









































 前回と同様、X6g 系は、apne1-az2 では利用できないようです。利用される場合は、念のためご注意ください。
前回と同様、X6g 系は、apne1-az2 では利用できないようです。利用される場合は、念のためご注意ください。
















