なろう系小説みたいなタイトルでこんにちは。技術4課の保田(ほだ)です。
13インチのメインモニター1枚で頑張るのが辛くなってきたのでモニターを注文しました。届くのが楽しみです。
導入
弊社では2月の半ばから極力オフィスに行かず在宅勤務を推奨しているので私はもう4ヶ月ぐらいオフィスに行ってません。
ところで、去年ぐらいまで私が所属していた課で新人さんが取り組む OJT 課題として、「 Raspberry Pi に人感センサーを取り付けて会議室の人の有無をモニタリングする」というものがありました。
AWS IoT Core に対して Raspberry Pi からデータを送信し、それを CloudWatch のメトリクスとして可視化、さらに SNS で通知してみよう、というものです。その過程で AWS IoT はもちろんのこと Raspberry Pi のセットアップや、簡単な Python のお勉強、 Git のお勉強ができるというカリキュラムです。
非常に楽しい課題なのでやりたいのですが、まずオフィスに行けないので Raspberry Pi が設置できない、そして設置しても自分しかいないと会議室の人の有無が常に「無」になってしまう……。
あ!そうだ! mockmock を使ったらいいんだ!というワケです。
mockmock とは
mockmock とは 株式会社Fusic(フュージック)社が開発する IoT 開発におけるテストを支援してくれるツールです。
平たく言えば IoT の仮想デバイスを画面ポチポチで簡単に何台も作成できて、異常系テストや負荷テストも簡単にできてしまうサービスです。
今回のお話で言えば Raspberry Pi を mock で置き換えてしまいます。
どんな mock が欲しいのか
mock を作るにあたってどんなデータを送るかを考えます。後程詳しくご紹介しますが、これは mockmock においてはデータテンプレートに定義する JSON の形式を決めることに相当します。
ある時刻において人感センサーが人を検出しているか / 検出していないかを取得したいので、以下のようなデータ形式を考えれば良さそうです。
{
"status": "1",
"datetime": "1593594616"
}
キー status として人がいる場合は "1"を、人がいない場合は "0" を取るようにします。
AWS IoT の設定
人感センサー(の mock )に対応させる AWS IoT の Thing と周辺リソース諸々を作成していきます。
IAM Role の作成
IoT Core が CloudWatch にデータを送信する権限を付与するような IAM Role を作成します。
マネジメントコンソールの [サービス] から IAM を開きます。
左ペインから [ロール] を選択し、[ロールの作成] ボタンをクリックします。
[ユースケースの選択] ではサービス名から [IoT] -> [IoT] を選択し、 [次のステップ: アクセス権限] をクリックします。次は何もせず [次のステップ: タグ] -> [次のステップ: 確認] までクリックし、最後にロール名を入力します。ここでは MotionDevRole とします。入力したら [ロールの作成] をクリックし作成を完了します。
Policy の作成
マネジメントコンソールの [サービス] から IoT Core を開きます。
左ペインから [安全性] -> [ポリシー] を選択します。画面右上に [作成] ボタンがあるのでクリックしてポリシーの作成画面を開きます。
ポリシー名は MotionDevPolicy とし、以下のように入力して [作成] をクリックします。
![]()
以下のポリシーが作成されます。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "iot:Connect",
"Resource": "*"
},
{
"Effect": "Allow",
"Action": "iot:Publish",
"Resource": "arn:aws:iot:ap-northeast-1:012345678901:topic/motion"
}
]
}
Thing の作成
IoT Core 上で認識されるデバイスの単位となる Thing (モノ)を作成します(開きっぱなしとは思いますが…)。
マネジメントコンソールの [サービス] から IoT Core を開きます。
左ペインから [管理] -> [モノ] を選択します。画面右上に [作成] ボタンがあるのでクリックしてモノの作成画面を開きます。[単一のモノを作成する] と [多数のモノの作成] を選択できますが、前者の [単一のモノを作成する] を選択します。
名前を MotionDev とします。その他の項目は何も触らず [次へ] をクリックします。
[モノに証明書を追加] の画面になりますので一番上の [1-Click 証明書作成(推奨)] を選択します。すると 1-Click で証明書が作成され、ダウンロードリンクが表示されたページへ遷移しますので、それぞれ以下をダウンロードします。(この状態のページでしかキーを取得できなくなるのでご注意ください)
- このモノの証明書
- パブリックキー
- プライベートキー
- AWS IoT のルート CA
ルート CA についてはリンクを開くと AWS のドキュメントに遷移します。 RSA 2048 ビットキーを選び中身をコピペしてローカルに rootCA.pem として保存しておきます。
[有効化] ボタンがありますのでクリックして有効化します。有効化されるとこのボタンが [無効化] ボタンに変化します。
[ポリシーをアタッチ] を選択します。作成済みのポリシーが選択できるようになっていますので、先ほど作成した MotionDevPolicy を選択してアタッチします。
[モノの登録] を選択すると、 Thing の作成が完了し一覧画面に遷移します。
AWS IoT Core のコンソール上の左ペインより [設定] を選択すると [カスタムエンドポイント] として以下の形式の文字列が表示されますので、これをメモしておきます。
xxxxxxxxxxxxxx-ats.iot.ap-northeast-1.amazonaws.com
これは後で mockmock の設定をする際に使用します。
Rule の作成
デバイス(の mock )から送信されたデータに対して IoT Core がどんな操作をするかを定めます。冒頭でも説明しましたように CloudWatch のメトリクスとして可視化したいので、そのように設定していきます。
マネジメントコンソールの [サービス] から IoT Core を開きます(やはり開きっぱなしとは思いますが…)。
左ペインから [ACT] -> [ルール] を選択します。画面右上に [作成] ボタンがあるのでクリックしてルールの作成画面を開きます。
名前を MotionDevRule とします。ルールクエリステートメントの SQL バージョンは 2016-03-23 を選択し、クエリ本文は以下のようにします。
SELECT * FROM 'motion'
この 'motion' はのちに mockmock 側で設定する Topic 名と一致している必要があります。
[アクションの追加] ボタンをクリックし、CloudWatch メトリクスにメッセージデータを送信する を選択します。すると必要な設定項目一覧が表示されますので、それぞれ次のように設定しいます。
| 項目名 |
設定値 |
| メトリクス名 |
MotionDev |
| メトリクス名前空間 |
IoT |
| 単位 |
Count |
| 値 |
${status} |
| タイムスタンプ |
${datetime} |
この Rule を実行するための IAM Role を選択する必要がありますので、 [選択] をクリックし、先ほど作成した MotionDevRole を選択します。
実はこのとき選択した Role にアタッチされたポリシーに CloudWatch にメトリックを送信するための API アクションを許可する記述がなくても [ロールの更新] を選択すれば自動的にマネージドポリシーを自動生成してアタッチしてくれます。
今回はすでにこの API アクションは許可されていますので、そのまま [アクションの追加] をクリックします。するとルールの作成画面に戻りますので [ルールの作成] をクリックして作成を完了します。
これで AWS 側の準備は完了です。
mockmock の設定
ここからは mockmock 側での準備(mock の作成、送信の開始)となります。
プロジェクトの作成
コンソールにログインして [プロジェクト一覧] から [プロジェクト作成] を選択します。
プロジェクト名を MotionDev とし、サーバータイプとして [AWS] AWS IoT Core を選択します。すると入力項目がいろいろと変化するので後は以下の値を入力・選択します。
| 項目名 |
設定値 |
| キャパシティ |
cn1 |
| プロトコル |
MQTTS |
| 送信先ホスト |
Thing の作成でメモしておいたカスタムエンドポイント名 |
| 証明書ファイル |
Thing の作成時に このモノの証明書 としてダウンロードしたファイル |
| 秘密鍵ファイル |
Thing の作成時に プライベートキー としてダウンロードしたファイル |
| Root証明書ファイル |
Thing の作成時に AWS IoT のルート CA としてダウンロードしたファイル |
| SSL/TLS |
TLSv1.2 |
入力が完了したら [登録] をクリックします。
今回は人感センサーによって取得した「人がいる( status が 1)」 or 「人がいない( status が 0)」の情報を送信したいので、0 と 1 をランダムに生成するような仕組みが必要です。
そもそも mockmock にはバリュージェネレータという機能があり、特定のルールに基づいて値を生成することができます。詳しくは公式のドキュメントをご参照いただければと思いますが、 GUI でグニグニいじったグラフに沿った値を(いい感じの揺らぎも考慮して)時系列で生成したり、緯度経度の位置情報を地図の UI からグラフィカルに定義できたり、いろいろ遊べます。
今回はその中の一つである バケットを使用すればそれが実現できそうです。
コンソールの左ペインから [バリュージェネレーター] -> [バケット] の右側にある [+] ボタンをクリックし新規作成画面を開きます。
バリュージェネレーター名を motion とし、送信ルールとして ランダム を選択します。データリストは以下のように入力します。
"0"
"1"
入力したら [登録] をクリックします。
冒頭で考えた、送信したい JSON データのテンプレートを定義します。
コンソールの左ペインから [データソース] -> [テンプレート] の右側にある [+] ボタンをクリックし新規作成画面を開きます。
テンプレート名を motion とし、[元になるjson] に以下を入力します。
{
"status": "1",
"datetime": "1593594616"
}
[登録] をクリックすると、この JSON の詳細な形式を定義する画面に遷移しますので、それぞれ以下のように編集します。
![]()
status の値を先ほど作成したジェネレーター motion から生成する、datetime は %s (UNIX 時間)をあてはめる、という設定をしている点にご注目下さい。
mock の作成
ようやく mock を作ります。まずはそれぞれのデバイス(の mock )を束ねる mockグループを作成します。
コンソールの左ペインから [mockグループ] の右側にある [+] ボタンをクリックし新規作成画面を開きます。
mockグループ名をmotion 、最大稼働時間 [sec] を 300 とします。(最大稼働時間を過ぎると mock は自動停止します。)後はデフォルトのままで [登録] をクリックします。
作成すると [mockステータス] のタブを開き mock ステータスを作成します(正常系も異常系も作れる!)。[mockステータス作成] をクリックし、それぞれ以下のように値を設定します。
![]()
ここで Topic を motion としたことで、 IoT Core の側に作成した Rule はこの mock が送信するデータを取得して操作(CloudWatch メトリクスに送信)できるようになります。最大送信間隔と最小送信間隔をどちらも 10 [sec] にしたので、きっかり10秒おきにデータを送信するようになっています。
入力したら [登録] をクリックします。試しにテスト送信してみたいので、 [テスト送信] 欄の [mock新規作成] をクリックし mock 作成画面を開きます。(これは [mock管理] のタブから mock を作成してそのあと [テスト送信] もできます。どちらでも大丈夫です。)
MQTTクライアントID の入力を求められますが空っぽのまま [登録] をクリックします(書いてない項目は勝手に作ってくれます)。ID が割り当てられて作成されているのが確認できます。これが mock を1台作成した状態です。
作成されたら [mock管理] のタブに移動しているので、再び [mockステータス] のタブへ移動します。すると先ほど作成した mock を使ってテスト送信ができるようになっていますので [送信] をクリックします。
![]()
[成否] が true だったら OK です。 [閉じる] で閉じましょう。
mock の実行
ついに作成した mock を使って疑似的に人感センサーを会議室に設置した状況を作り出してみます。
[mock管理] のタブ内に表示された mock を [操作] -> [起動] をクリックします。
![]()
起動して良いかの確認ウィンドウが出るので OK しますと、 mock が起動し始めます。
それでは AWS のマネジメントコンソールを様子を見に行きましょう。
[サービス] から CloudWatch を選択して開き、 [メトリクス] を選択します。[すべてのメトリクス] のタブ内に [IoT] という項目が表示されているはずなのでそれを選択します。 [ディメンジョンなしのメトリクス] -> [MotionDev] にチェックを入れます。[グラフ化したメトリクス] のタブに先ほど選択した MotionDev というメトリクスが表示されるようになるので、 [統計] や [期間] の項目はいろいろ選べますが、まずはそれぞれ「最大」と「1分」を選んでみます。
画面上部のグラフを見てみます。
![]()
1分以内に観測できた一番大きい数字をプロットさせています。稼働させ始めてからどこかのタイミングで(仮想の)人を観測したようでね。例えばこの [統計] を「平均」にすると人がいることの方が多いのか、少ないのかが判断できそうです。
ちなみに送信しているデータは mockmock のコンソール側からも確認できます。二つ前の添付画像において [モニタリング] というボタンがありますのでそれをクリックするとこのような画面が表示されます。
![]()
そもそも mock がちゃんと動いているか、どれぐらい送信しているか、どんなデータを送信したかが確認できます。
これで Raspberry Pi も人感センサーも使わずさらにはオフィスにすら行かずに「人感センサーでオフィスの人がいるかいないかを観測する」ということが再現できました。
オフィスに人が戻り始めたら実際のものを用意してやって証明書や秘密鍵をそちらにも移してやれば OK です。
研修課題は CloudWatch と SNS を連携させるところまでやりますが、これについては mock が直接関係しないので省略します…。
さらなる話題
これで最低限のことは実現できましたが、 mockmock ではもっといろんな状況を作り出せます。まず簡単に台数が増やせるのでその分 Raspberry Pi と人感センサーを買うお金が減らせてとても便利です。
またデータが取得できない状況(異常系)を作って一定確率で異常系に遷移してしまうようなケースも実機でやるには厳しいことが多いです。これは状態遷移の機能で実現できます。夢が広がりますね!
まとめ
ここまで丁寧に説明してきたので長い道のりに思えますが(書いてる私は特に)、AWS IoT 側の設定はともかく mockmock 側は、次のような定番の流れがあることがやっているうちに分かってきます。
- プロジェクトを作りーの
- ジェネレータ作りーの
- それを元にテンプレート作りーの
- それを送信するようなステータス作りーの
- そのステータスに体操する mock 本体を作りーの
- あとは送信
既存の設定をコピーするという機能も充実していますので、そのあたりもなかなかうれしいです。
あと、そもそも公式ドキュメントがとても丁寧なので読んでみて下さい。
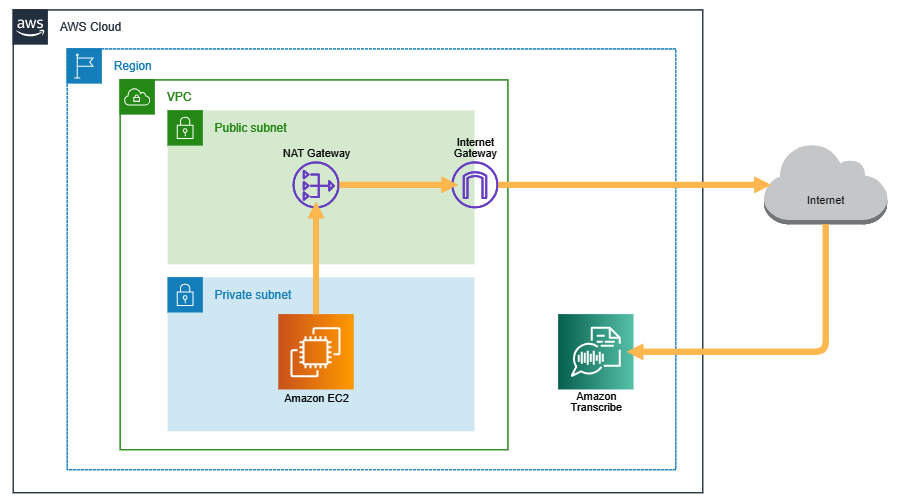
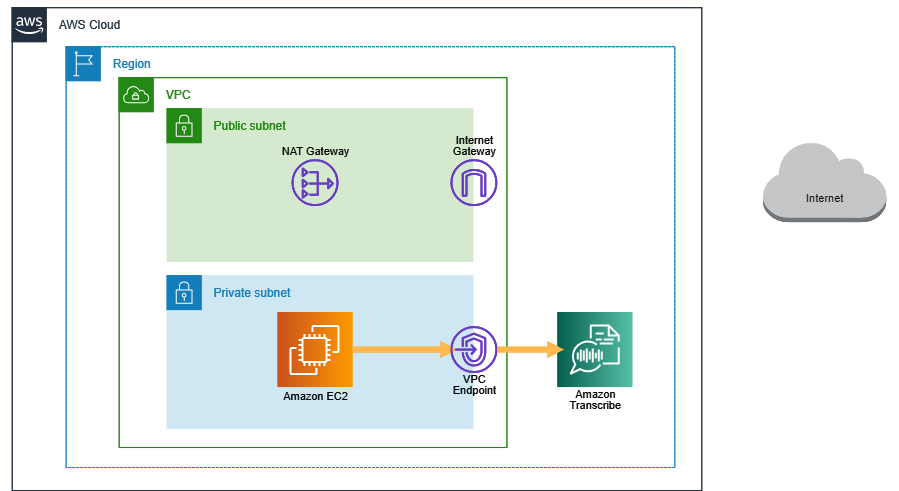

 詳細タブに記載されていたDNS名を名前解決してみると、172.31.81.26であることを確認しました。
詳細タブに記載されていたDNS名を名前解決してみると、172.31.81.26であることを確認しました。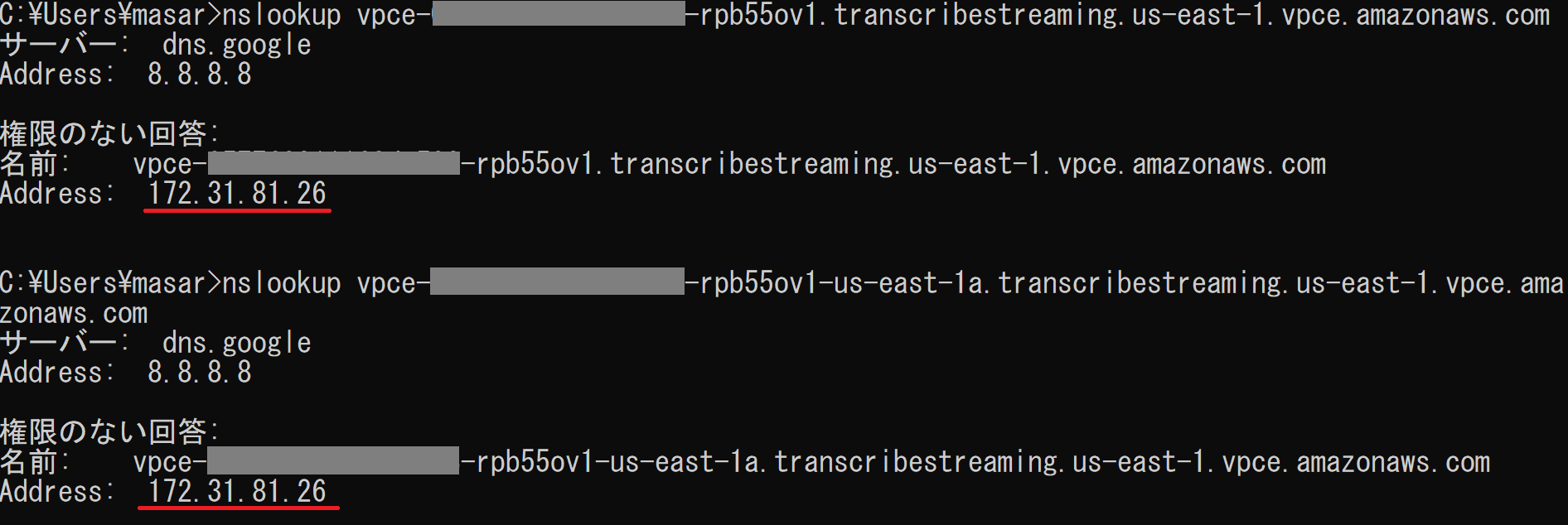


























































 データボリュームがアタッチされていないインスタンスがあったら、
データボリュームがアタッチされていないインスタンスがあったら、














































